个人感觉还是比较有意思的一个工作。
Paper:https://arxiv.org/abs/2006.03511
Code:https://github.com/facebookresearch/TransCoder
Facebook 用 XLM 对代码进行预训练,用了无监督翻译的思想,达到 AI 自动翻译代码的效果。虽然理论上图灵完备的语言都能互相转换,而且像 TypeScript 之类的语言通常自带 Transcompiler 将自己编译到 JavaScript 等已经有解释器/编译器的语言,但是这需要 Transcompiler 作者对源语言和目标语言都非常熟悉,而且需要编写大量规则。而完全手动翻译则更加不可取。所以尽管 AI 翻译的准确率比较低,但是用 AI + 人工调整的方式还是具有一定优势的。
但是问题在于代码几乎没有平行语料可以用,也就是很难找到大量的 C++ 到 Java 或者之类的对应的代码,所以最好是使用无监督翻译的思想。这篇论文假设代码都能映射到同一个隐空间,用了 XLM 的思想,所有语言对都用同一个模型翻译。
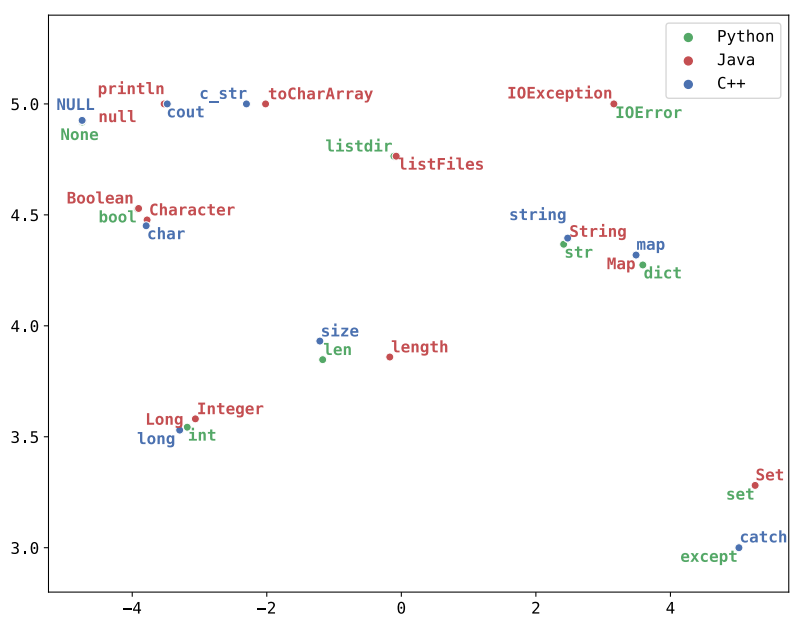
这种思路关键在于语言之间需要有锚点(Anchor Point),否则模型很难对齐 Embedding。像英文-中文就比较难对齐,因为用的字母表都完全不同,而英语-法语就比较容易对齐。编程语言中的关键词、标识符通常都是用英文单词写的,所以同理也比较适合 XLM 对齐。(但是可能有拼音、ACM 风的变量名)
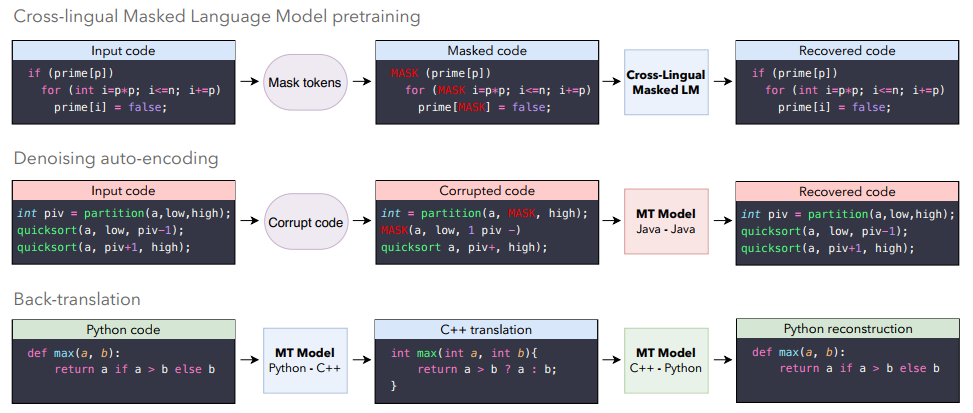
模型训练主要分为三个步骤:
- 首先用 XLM 训练一个 MLM
- 然后用 DAE 训练自己到自己的翻译模型(尽管源代码有被修改但是模型还能够恢复正确的代码)
- 最后就是经典的回译了
然后论文提到以前的评价指标是 BLEU,这也是机器翻译常用的指标。但是对于程序来说,只要运行结果正确就可以了,变量名之类的可以完全不同。所以作者从 GeeksForGeeks 搜集了一些算法题,然后将不同版本的答案作为测试用的平行语料,最后就是用 OJ 的思想来对翻译后的代码进行正确性验证,随机生成不同样例,只要能 AC 就算翻译成功。
实验部分
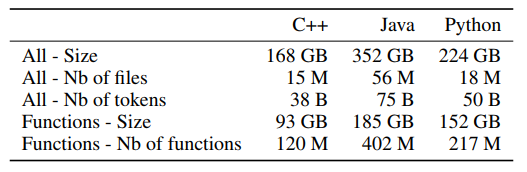
作者用了 Google Cloud 上的 Github Repos 数据集,具体如何下载可以到代码仓库的 README 查看。实验只做了 C++、Java、Python 的部分。刚好这三种语言比较流行,代码量比较大,而且有动态语言和静态语言,覆盖面比较广。测试的时候以函数为粒度进行测试。

关于数据预处理,传统的机器翻译通常对所有语言都使用同一个 Tokenizer,这样可以尽可能减少词表大小,增加词汇重叠度。但是对于编程语言,行不通,因为 C++ 缩进是可以忽略的,但是 Python 是不可以的,而且像 && 和 || 这种操作符 Python 也没有。所以不同的语言要使用不同的 Tokenizer,然后再用 BPE 来将 Token 分解为 Subword。
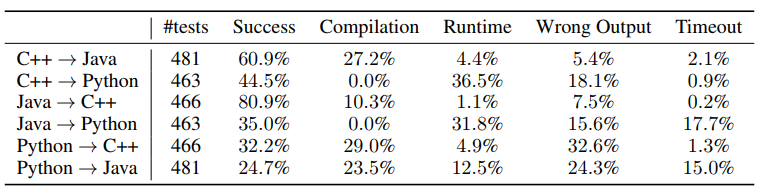
实验结果可以看到,静态语言到静态语言的准确率还是很高的,而动态语言到静态语言相比之下就相当低了。这也很好解释,因为动态语言通常没有类型标注,翻译到 C++、Java 之类的比较困难。
作者还和 j2py 还有一个 Tangible Software 的商用的 C++ 到 Java 的翻译器作了比较。后面的翻译器能处理像 vector 到 List 之类的映射。

可以看到准确率在 Greedy Search 情况下不如 Baseline,但是加了 Beam Search 的话准确率可以大幅提升,不过这是算 Beam Search 所有搜到的结果,只要有一个成功就算翻译成功。Top 1 则是取 Log Prob. 最大的,可以看到相比不取,掉了很多准确率,说明模型会把不正确的程序的概率计算成比较大的。



这里是作者给出的几个成功的样例,可以看到模型能够学习到不同语言标准库和原始类型的映射关系。即便是 Python 到 Java,在一些情况下仍然能正确推导一些变量的类型。

和 Baseline 比较,模型对于标准库函数映射更胜一筹。
奇怪的是,一些非常简单的函数反而会翻译错误:

主要是不同语言语法和标准库函数一些细微的差别导致的。
想法
AI 转译主要是难以保证结果的稳定性而且不好 Debug,程序本来就是结构化的,可以写 Transcompiler 准确翻译。不过写 Transcompiler 需要编码大量规则,我觉得可以尝试从模型中抽取标准库函数和语法之类的对齐关系来辅助编写 Transcompiler。
而且例子给出的基本都是只用了标准库函数的代码,现实应用中通常会使用大量的第三方库或者框架,不知道模型对于这种场景是否能很好应对。
个人感觉比较新颖吧,但是实用性可能还有待考究。作者说可以训练一些从旧代码语言比如 COBOL 翻译到 Java 的模型,但是我感觉有可能旧代码的量不是很够训练。