@王润基 在 这篇文章 里介绍了如何使用 Async Rust 封装 UCX 通信库。在那篇文章中,rjgg 已经介绍过 UCX 的机制,这里就不再重复。和 Rust 相提并论的 C++ 20 中也提供了 co_await 等异步编程语法关键词,我们可不可以也用它来封装异步通信、降低编程复杂度,而性能开销又有多大呢?答案是:可以,而且是零开销封装!
和 Rust 的异步 Future 需要一个 Runtime 负责 poll 不同,C++ 的协程仅仅是帮助编译器进行代码变换的一个语法,也就是说 C++ 的协程实际上是不需要借助类似 Tokio 等通用运行时来驱动协程运行,而是可以完全由用户决定运行的时机。正如使用 C++ 20 封装 RDMA 操作中提到的,我们只需要开启一个轮询线程,不断地轮询事件的发生,然后调用预先定义好的回调函数,就能让协程运行起来了。
具体到 UCX,这个驱动协程运行的函数就是 ucp_worker_progress ,通过不断调用这个函数,UCX 会检查 IO 事件是否完成,并调用我们发起请求时注册的回调函数。我们只需要将编译器提供的继续运行被暂停协程的函数地址保存到上下文中,并且在回调函数中调用继续运行的函数,就能驱动协程的运行了。UCX 中提供了一系列 *_nbx 函数用来发起异步操作。这些函数调用之后不会阻塞,如果操作没有完成,就返回一个地址,我们后续可以通过轮询这个地址的状态,来检查我们的操作是否完成。也就是:
ucp_request_param_t param = {};
// ...
auto request = ucp_*_nbx(..., ¶m);
while (ucp_request_check_status(request) != UCS_OK)
ucp_worker_progress(worker);但很显然,如果我们使用这种阻塞的方法去轮询的话,并发度会很低,效率肯定不高。为了充分发挥 UCX 的异步性能,我们需要想办法把 C++ 提供的协程语法和回调机制结合起来。正如使用 C++ 20 封装 RDMA 操作中提到的,所有的异步操作的最终实现形态就是 awaitable,那么实现思路就很清晰了
- 在构造函数中,我们保存此次操作需要的参数。
- 在
await_ready中发起操作,将当前awaitable指针保存到请求上下文。如果操作立刻完成了,那就可以节省一次打包状态的开销。 - 在
await_suspend中,我们简单的将coroutine_handle保存到awaitable中。 - 在
await_resume中,将操作的结果返回。对于stream_recv,需要返回接收的字节数。对于tag_recv需要返回接收的字节数和发送方的 tag。
另一个需要注意的地方是,每次需要发起操作的时候都需要构造 awaitable 并调用相关函数,也就是 awaitable 处于热点路径上,我们必须尽可能减小 awaitable 的尺寸,减少代码分支,并且在传参的时候尽量避免开销大的复制操作(例如 shared_ptr 的复制,以牺牲安全性为代价换取性能)。
最终封装完成的代码见:https://github.com/howardlau1999/ucxpp
目前支持的功能有:
- UCP:Tag/Stream Send/Recv、RMO
性能测试
实现完成后,我们来看看 UCX++ 的性能如何。使用协程,可以很方便地就写出高并发的测试程序。
测试使用了两台物理服务器进行,它们的软硬件配置相同。测试环境详情:
- OS: Ubuntu 22.04 (5.15.0-46-generic)
- CPU: Intel(R) Xeon(R) Gold 6230N CPU (1 socket, 20 physical cores, 40 logical cores)
- RAM: 192 GB DDR4 2666
- HCA: Mellanox ConnectX-4 Infiniband 56G
- Compiler: gcc (Ubuntu 11.2.0-19ubuntu1)
- UCX: v1.13.0 (
./contrib/configure-release) - Infiniband Driver: MLNX_OFED_LINUX-5.6-2.0.9.0
这里就简单测试一下小包和大包的性能。Baseline 就是 UCX 附带的 ucx_perftest,这里运行的是 tag_bw 测试,测试方法是客户端不停向服务端发起 tag_send 请求,是单向的测试。对于 8B 和 256B 的测试,并发数为 1,对于单次发送 4K 和 64K 的测试,并发数为 32。测试程序全部都是单线程的,通过 taskset 以及内核的 isolcpus 选项单独隔离一个物理核进行测试。

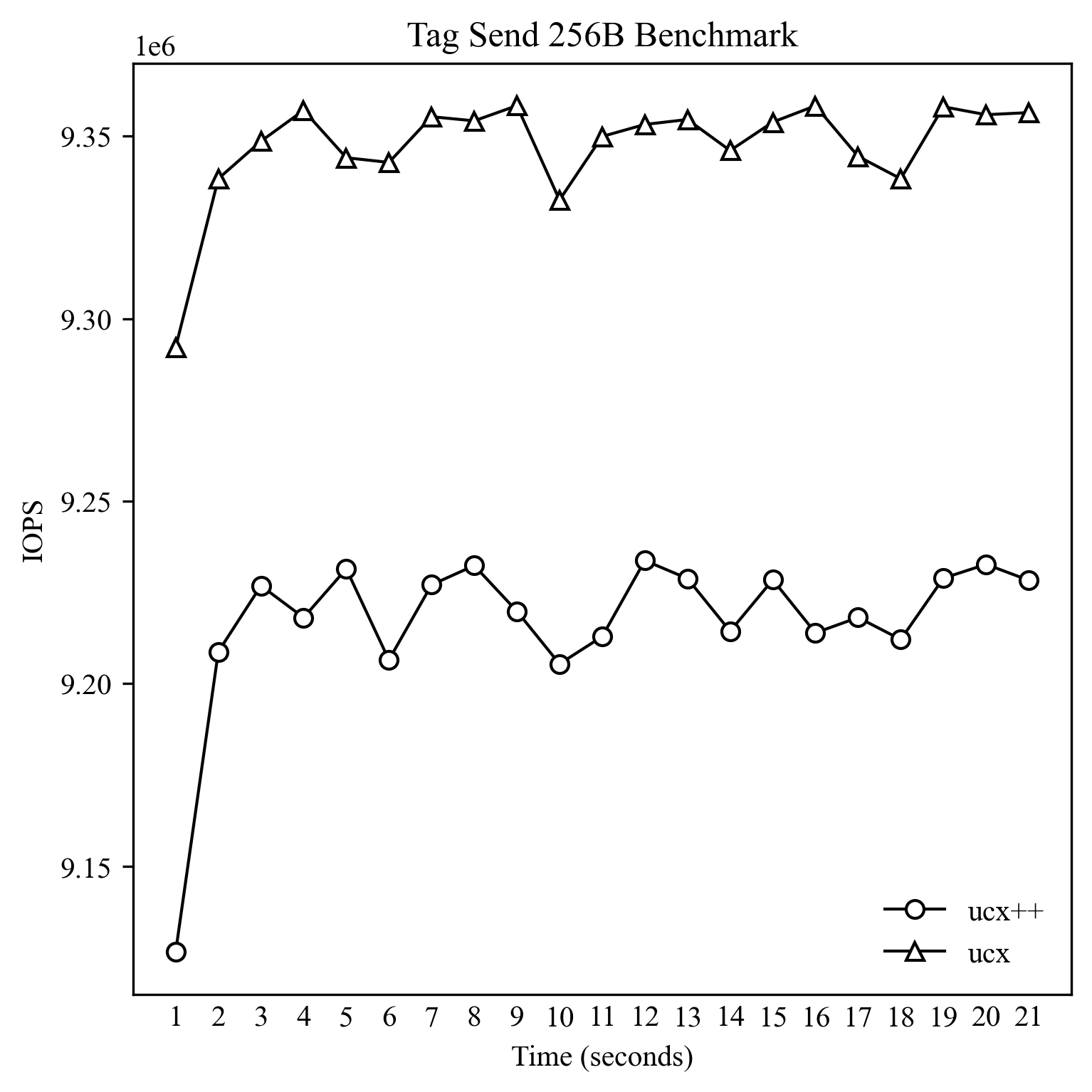
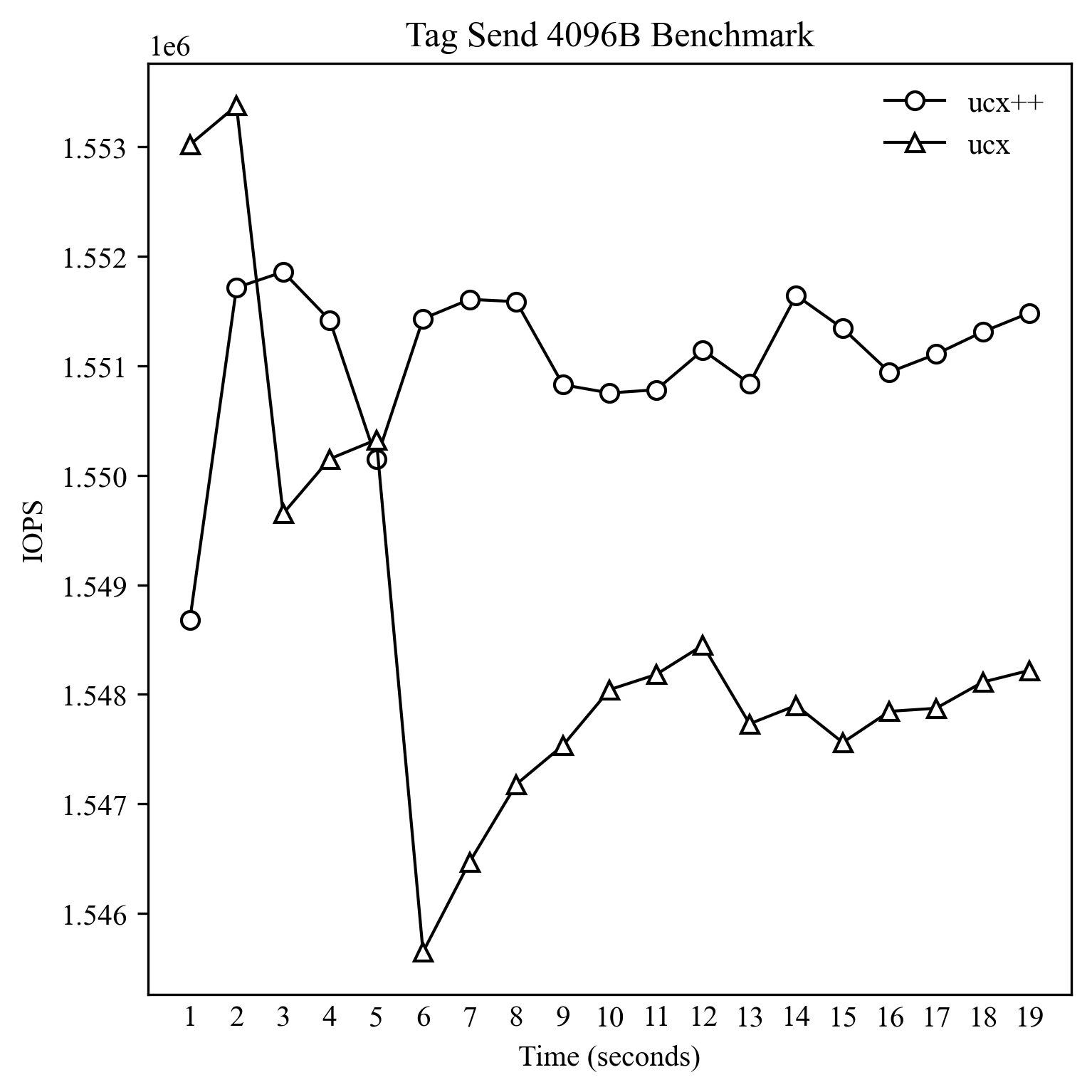
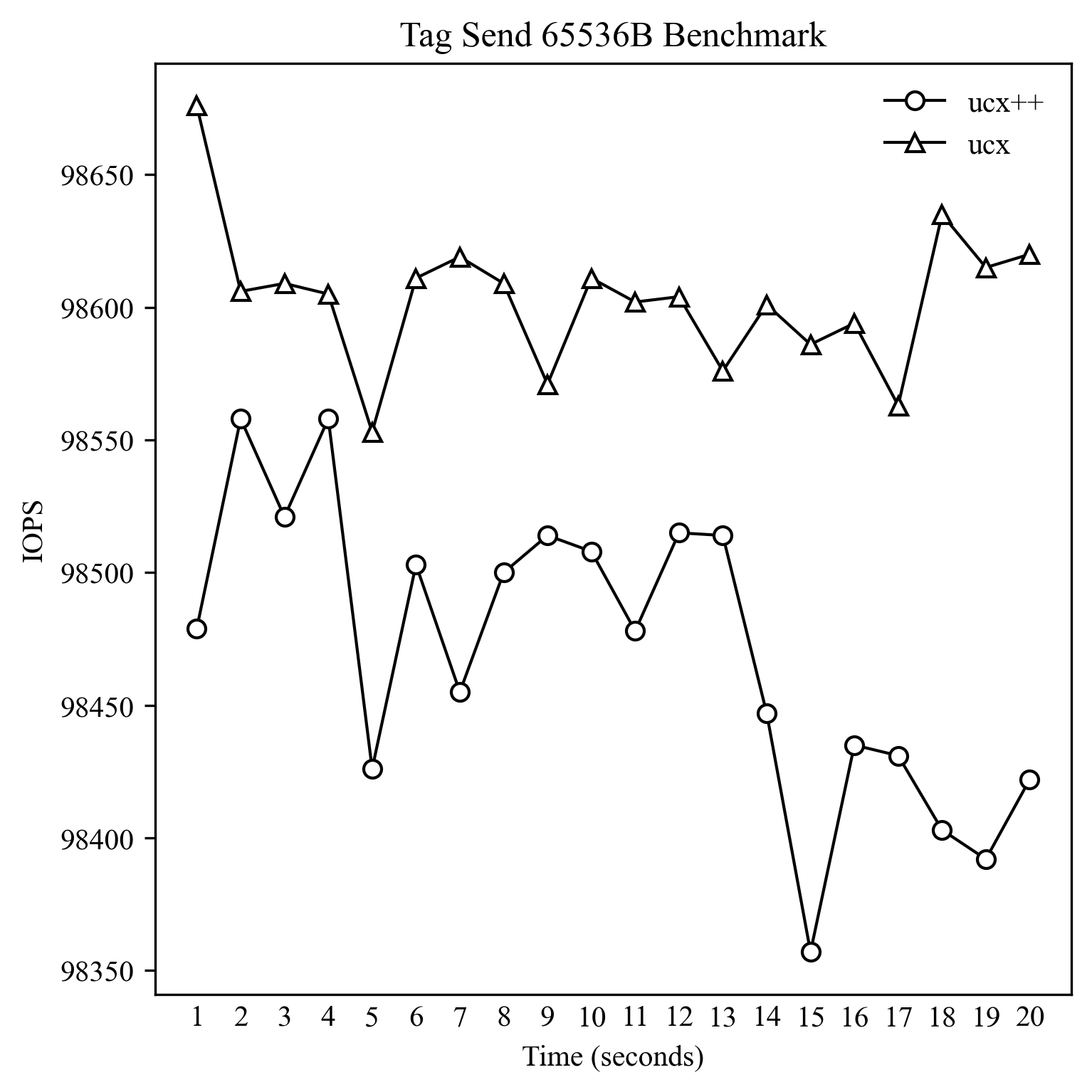
可以看到基本上 IOPS 差距为 1% 以内,这其中还有计时方法的影响,所以可以放心使用 UCX++ 而不用担心性能问题。
重铸 C++ 荣光,我辈义不容辞!