目录
目前,PyTorch 官方已经准备逐渐放弃对 DataParallel 的支持。而且受限于 Python 的 GIL,DataParallel 采用的多线程模型不能充分发挥多核性能。PyTorch 官方建议大家使用 DistributedDataParallel(简称 DDP),即使你只有一台服务器。这个类使用上会复杂一些,PyTorch 官方教程写的比较复杂,这个教程将步骤拆解一下,方便入门。
DDP 原理
DDP 的原理是开启多个进程,每个进程占用一张卡来进行训练。在训练开始之前,每个进程需要加载相同的模型权重,这样大家就有同样的起点。然后,训练过程中,每个进程单独加载不同的训练集的子集,进行前向传播并进行反向传播求解梯度。最后,所有进程开始互相通信,交换其他所有进程的梯度(All-Reduce Sum),并求平均。最后,每个进程都使用平均后的梯度更新自己的模型参数。由于每个进程更新的梯度都是一样的,所以在每次梯度更新后所有进程的模型参数都是一样的。
同步梯度的时候不像 DataParallel 那样在一张卡上计算更新梯度之后再将模型参数下发(Parameter Server 模型),这样不仅会造成某张卡负载更高,还有可能会因为传输过多碰到网络瓶颈。所以 DDP 采用了 Ring AllReduce 的方法,每张卡只和自己的邻居交换梯度。
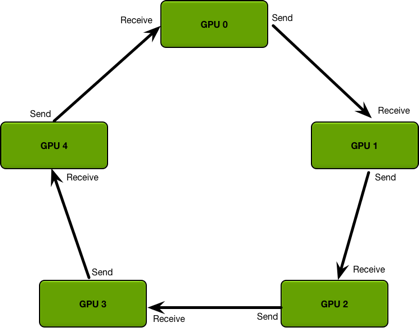
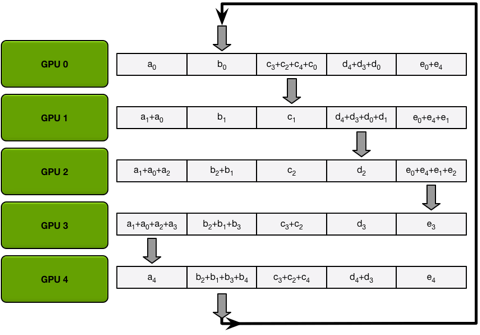
比如 1 卡只会接收从 0 卡发来的梯度,只会发送梯度到 2 卡。同时,传输的时候会将数据分块,数据量为 D 的时候,N 个进程在最开始的 N-1 轮传输会发送和接收 D/N 的数据量,然后后面再用 N-1 轮,每个进程将每一块平均好的数据按照环形发送到下一个进程,同样是 D/N 的数据量。这样总共需要传输 2D*(N-1)/N 的数据量。可以看出,数据传输总量基本和 N 无关,所以用 DDP 有良好的扩展性,有钱任性开几百个进程训练数据传输都不会成为瓶颈。
没错,DDP 的原理就是这么简单,下面看看怎么用。首先介绍几个 DDP 里会碰到的概念(括号里是后面会用到的环境变量名称):
- World Size(
WORLD_SIZE):总共有多少个进程参与训练,如果你有两台服务器,每台服务器有四张卡,那么 World Size 就是 2 x 4 = 8。 - Rank(
RANK):标识一个进程的序号,从 0 开始。按照上面例子的配置,第一台机器上的 0, 1, 2, 3 卡对应的进程序号就是 0, 1, 2, 3,第二台机器上 0, 1, 2, 3 对应的进程序号就是 4, 5, 6, 7。需要确保每个进程的序号没有重复。其中 0 号进程为主进程,负责一些同步操作的通信。 - Master Address(
MASTER_ADDR):标识主进程所在的机器 IP 或者主机名,例如10.0.0.1或者gpu-server1,每一个进程都填一样的就可以了。假如你只有一台服务器的话,填127.0.0.1或者localhost也可以。 - Master Port(
MASTER_PORT):标识主进程应该监听哪一个端口,随便选择一个没有被占用的端口就好了,比如 23333、10086。一样是每个进程都填一样的就好了。 - Local Rank(
LOCAL_RANK):标识一个进程在本机上是第几个进程,不是必须的参数。可以简单理解为这个进程占用的是一台机器上的第几张卡。按照上面例子的配置,第一台机器上的 0, 1, 2, 3 卡对应的 Local Rank 就是 0, 1, 2, 3,第二台机器上 0, 1, 2, 3 对应的 Local Rank 就是 0, 1, 2, 3。可以看出,这个和 Rank 不同,是可以重复的,只用来标识这是一台机器的第几张卡。另外,假如你用了CUDA_VISIBLE_DEVICES的话,需要注意 Local Rank 就不一定和卡的序号相同了。比如你设定了CUDA_VISIBLE_DEVICES=2,3,你的 Local Rank 分别应该设置成 0, 1。
这里提一下,既然 Rank 已经能够唯一标识每个进程,为什么还要 Local Rank?主要是在操作文件的时候还有设定进程使用的卡的时候会用到。因为可能你的服务器之间没有共享的文件系统,那么像数据集下载、模型保存这种操作就需要每台机器自己进行同步了,Local Rank 就可以当成这台机器上的本地主进程了。
代码实战
为了简化代码,下面的代码片段默认你使用 DDP,但是一般来说,为了方便 debug,在开发阶段用一张卡就能调,需要你自己写判断是否使用分布式训练。比如加一个 if 判断没有传上面的环境变量就使用 DataParallel 或者单卡来训练。
初始化进程组
首先,你需要在你的脚本里一开始就告诉 PyTorch,你要进行分布式训练。在开始训练前(通常在 parser.parse_args() 之后),添加这么一行代码:
torch.distributed.init_process_group(backend="nccl")
local_rank = int(os.getenv("LOCAL_RANK"), -1)默认情况下,PyTorch 会读取上面提到的环境变量,尝试连接到主进程进行通信。一般多 GPU 训练使用 nccl 后端即可。
设置使用的卡
初始化进程组后,设定本进程使用哪一张卡:
torch.cuda.set_device(local_rank)
device = torch.device("cuda", local_rank)加载模型并转移到卡上
model = torch.load("model.bin", map_location="cpu")
model.to(device)这里使用 map_location="cpu" 的原因是避免不小心将模型加载到同一张卡上,因为 PyTorch 在保存模型的时候会同时保存这个模型在哪个设备上,一般来说只有主进程会保存,所以如果直接加载的话会将模型复制几遍加载到主进程的卡上,分分钟爆显存。
使用 DDP 包装模型
直接使用 DistributedDataParallel 类包装即可。需要注意的是,如果使用混合精度训练,需要先用 amp 包装模型,再使用 DDP 包装模型:
if fp16:
try:
from apex.optimizers import FusedAdam
from apex import amp
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use distributed and fp16 training.")
optimizer = FusedSGD(model.parameters(),
lr=learning_rate)
model, optimizer = amp.initialize(
model,
optimizers=optimizer,
opt_level=fp16_opt_level,
keep_batchnorm_fp32=False,
loss_scale="dynamic" if loss_scale == 0 else args.loss_scale,
)
model = DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)包装数据集采样器
train_dataset = TensorDataset() # 每个进程加载一样的数据集
train_sampler = DistributedSampler(train_dataset)
train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=batch_size)训练
这一部分没有什么特别的,按照通常做法进行前向传播,反向传播,优化器更新参数即可。需要注意的是,为了保证每个进程采样过程随机数种子一样,需要在每个 Epoch 前设置 Sampler 的 Epoch:
for epoch in range(num_train_epochs):
train_sampler.set_epoch(epoch)
for x, y in train_dataloader:
x = x.to(device)
y = y.to(device)
outputs = model(x)
loss = loss_fn(outputs, y)
loss.backward()
optimizer.step()这样就完成了多卡训练代码的编写,下面看看怎么启动分布式训练。
注意事项
多进程读写文件同步
如果你的代码有输出或者写文件的操作,需要特别注意进程之间不要同时写一个文件,否则会造成数据错乱。一般来说,可以指定 local_rank == 0 或者 torch.distributed.get_rank() == 0 的进程来写。
判断是否分布式训练
可以使用 torch.distributed.is_available() and torch.distributed.is_initialized() 判断,不是多进程的情况下就可以不需要担心多进程文件读写同步的问题了。
启动训练
手动启动
这里还是假设你有两台服务器,每台四张卡,分别叫 gpu-server1 和 gpu-server2。
在 gpu-server1 上:
export MASTER_ADDR=gpu-server1
export MASTER_PORT=10086
export WORLD_SIZE=8
RANK=0 LOCAL_RANK=0 python train.py
RANK=1 LOCAL_RANK=1 python train.py
RANK=2 LOCAL_RANK=2 python train.py
RANK=3 LOCAL_RANK=3 python train.py在 gpu-server2 上:
export MASTER_ADDR=gpu-server1
export MASTER_PORT=10086
export WORLD_SIZE=8
RANK=4 LOCAL_RANK=0 python train.py
RANK=5 LOCAL_RANK=1 python train.py
RANK=6 LOCAL_RANK=2 python train.py
RANK=7 LOCAL_RANK=3 python train.pyPyTorch 的分布式训练进程会等待所有进程都准备完毕后才会继续往下执行,所以可以手动执行上面的脚本。
使用 PyTorch 启动工具启动
PyTorch 提供了一个 torch.distributed.launch 帮助我们启动进程。
在 gpu-server1 上:
export MASTER_ADDR=gpu-server1
export MASTER_PORT=10086
python -m torch.distributed.launch --use_env --nproc_per_node=4 --nnodes=2 --node_rank=0 --master_addr=$MASTER_ADDR --master_port=$MASTER_PORT train.py在 gpu-server2 上:
export MASTER_ADDR=gpu-server1
export MASTER_PORT=10086
python -m torch.distributed.launch --use_env --nproc_per_node=4 --nnodes=2 --node_rank=1 --master_addr=$MASTER_ADDR --master_port=$MASTER_PORT train.py其中 --nproc_per_node 指的是你每个服务器上想启动多少个进程,一般来说每个服务器有几张 GPU 就填几,--nnodes 表示你有几台服务器,--node_rank 指的是当前启动的是第几台服务器,从 0 开始。--use_env 表示 Local Rank 用 LOCAL_RANK 这个环境变量传参,如果不加这个选项,会在你的训练脚本之后额外添加一个 --local_rank 0 的命令行参数。
这个工具其实就是帮你计算 WORLD_SIZE = nproc_per_node * nnodes,然后执行一个循环,启动本机进程
for local_rank in range(nproc_per_node)
RANK = nproc_per_node * node_rank + local_rank
# 设置环境变量,启动训练进程
subprocess.call(...)这个脚本适合你的每台服务器上都有一样数量的卡,如果不是的话需要自己手动计算 Rank 和 World Size 按照第一种方法启动。
通过 Slurm 启动
如果你的服务器集群用 Slurm 作为作业管理软件,可以参考下面的 SBATCH 脚本来启动 PyTorch DDP 分布式训练:
#!/bin/bash
#SBATCH -N 2
#SBATCH --ntasks-per-node=1
#SBATCH -p gpu_v100
#SBATCH --output=joblog/R-%x.%j.out
#SBATCH --error=joblog/R-%x.%j.err
# Load anything you want
module load cudnn/7.6.4-CUDA10.1
export MASTER_ADDR=`/bin/hostname -s`
# 自动找一个空闲端口
export MASTER_PORT=`netstat -tan | awk '$1 == "tcp" && $4 ~ /:/ { port=$4; sub(/^[^:]+:/, "", port); used[int(port)] = 1; } END { for (p = 10000; p <= 65535; ++p) if (! (p in used)) { print p; exit(0); }; exit(1); }'`
srun run.slurm.sh其中 run.slurm.sh 参考内容如下:
#!/bin/bash
python -m torch.distributed.launch \
--nproc_per_node=4 \
--nnodes=${SLURM_JOB_NUM_NODES} \
--node_rank=${SLURM_NODEID} \
--master_addr=${MASTER_ADDR} \
--master_port=${MASTER_PORT} \
train.py这个其实就是用 srun 在每台服务器上执行启动脚本,脚本里传递 Slurm 的环境变量给启动工具。
完整代码可以到 https://github.com/howardlau1999/pytorch-ddp-template 参考。