Berkeley 的 RISELab 最近又搞了个大新闻,在 The Sky Above The Clouds 论文中提出了 Sky Computing 的概念。总的来讲,尽管目前市场上有许多云服务可供选择,但是不同云服务使用的 API 不同,数据在不同云服务之间迁移也很麻烦,需要用户自己处理数据的迁移和不同云服务 API 调用的编写。为了更方便地使用不同云服务厂商的优势服务,需要有一个中间层来连接不同的云服务,并向用户提供一个统一的 API 来描述任务,由中间层来负责在不同云之间调度服务。
举个例子,如果用户想使用脱敏的线上数据训练一个机器模型并部署,那么他可以先在 Azure 云上进行数据脱敏,然后使用 GCP 云的 TPU 快速低成本地训练模型,然后将训练好的模型传输到 AWS 云上使用 T4 提供线上服务。
这样做的好处一是可以让使用云服务更加简单,从而扩大云服务的市场;二是可以促进更加专门的云服务;第三是允许整合不同的计算资源;第四则是出于合规性的考虑,例如对于数据存放位置在不同国家地区可能有不同的要求。
但是这个中间层并不是要重新定义一个统一的 API,然后让不同云厂商去实现,相反,它是定义了一套兼容特性集合,实现了相应特性的云服务可以加入到 Sky 中,而用户则可以在任务中指定需要的特性,由中间层自动决定可以调用哪些云服务。作者也希望未来能够提供开源的测试用例,用来测试不同的云服务是否兼容某个特性。
| 分区多云 | 可移植多云 | Sky | |
|---|---|---|---|
| 在不同的云上运行相同的应用 | 否 | 是 | 是 |
| 对用户来说云是否透明的 | 否 | 否 | 是 |
| 统一 API(所有的云提供同样的 API) | 否 | 是 | 否 |
| 提供不同级别的 API | 是 | 否 | 是 |
Sky 的目标并不是想要提供完整的兼容性在所有的云上运行所有的应用,而是提供一部分兼容性,使得一部分应用可以在一部分的云上运行。这是由于提供太强的兼容性会使得标准过于复杂而难以实现,并且可能阻碍创新,放宽兼容性的要求可以使得 Sky 更有实用性,也允许创新的出现。
Sky 希望用户感知不到云服务的存在,用户无需和云服务厂商打交道。虽然现在也有 Kubernetes 这种分布式集群管理调度软件,但是它没有办法让用户不关心云服务的细节,用户还是需要自己到云服务厂商购买服务并部署软件,而且它也不能自动打通不同云服务,用户想要在不同的云上运行应用还得自己手动迁移数据。Sky 则免除了这些烦恼,用户只需要指定任务的运行脚本等,然后让 Sky 自动完成即可。
Sky 并不是对未来的被动预测,而是号召大家一起来实现这个宏图,构建一个细粒度的双边市场,避免价格战或者公司勾结,并在初期推出“杀手应用”来推进 Sky 的使用。例如机器学习就是一个可能的杀手级应用,用户可以使用 Ray 配合 Sky 在不同的云上同时进行超参数搜索,而无需分别编写不同的云 API 脚本。
一开始 Sky 支持的任务可能相当有限,例如只支持使用 DAG 描述的批处理任务,同时支持的云特性也比较有限,可能只支持 GPU 等。这样做可以让开发者节省精力专注在常用的应用场景中,随着使用人群的扩大,再根据需求排定优先级开发其他的功能,也就是使用一种类似“敏捷开发”的方法来迭代系统。
而这个中间层重要的一个组件就是优化器,就和数据库中的优化器一样,负责将用户的输入根据不同云平台的成本以及迁移开销,转换为实际的执行计划,从而最小化用户的成本。虽然现在用户也可以自己按照一定的方法来计算,但是当任务变得复杂之后计算也会变得困难,同时云服务的市场价格可能随时变动,让计算机去计算更合适。优化器生成执行计划后,先由分配器在不同的云服务预留资源,如果预留失败,就让优化器重新生成计划,然后执行器在预留的资源中真正地执行任务。
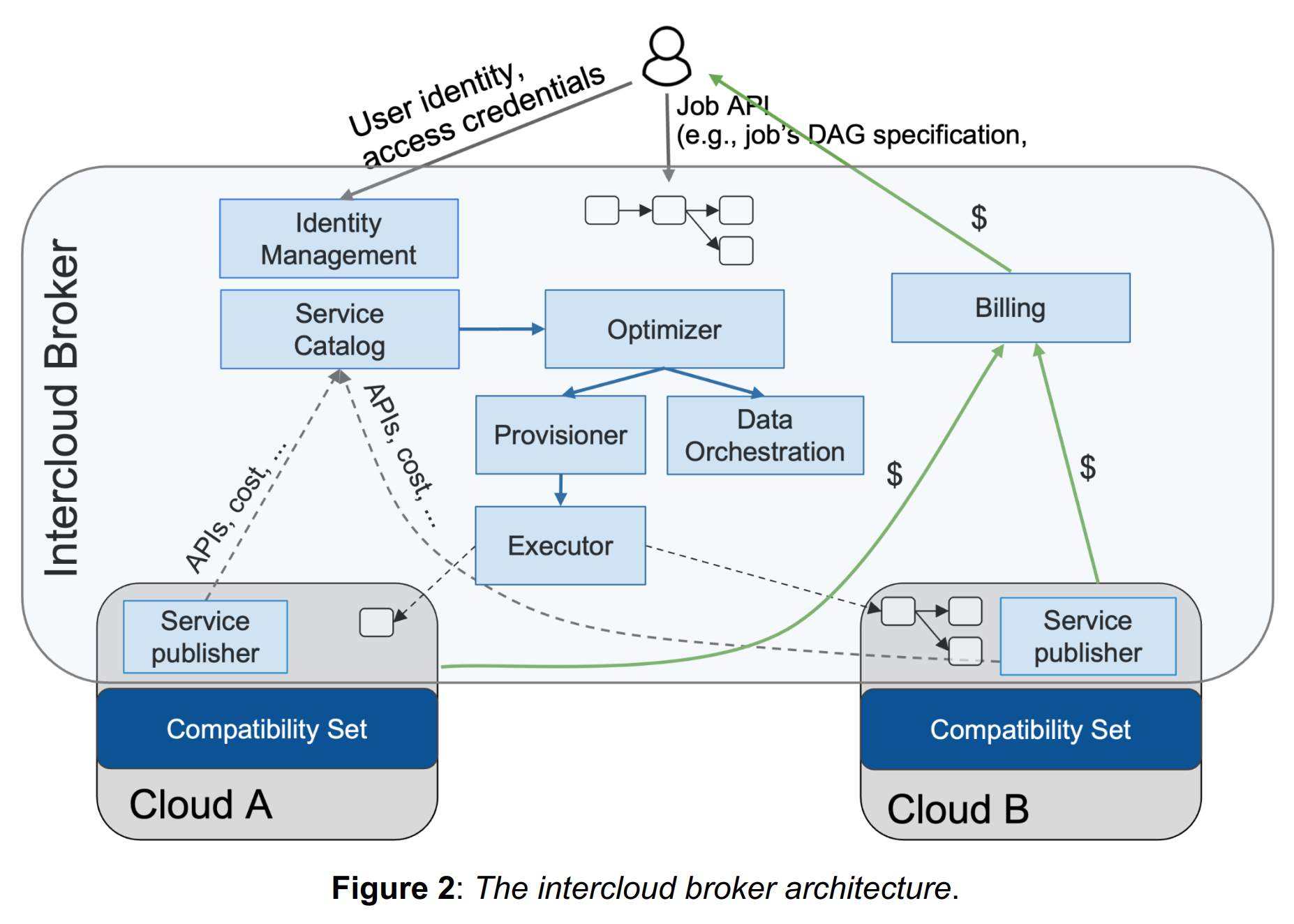
而在未来,作者展望云服务厂商之前可以达成对等协议,从而使得数据在对等的云服务之间传输不需要额外的费用,进一步促进 Sky 的发展,降低用户的使用成本。
总的来说,随着云计算的成熟,以及 Serverless 的成熟,能让用户能快速上手,不用纠结选择什么云服务的什么实例规格,只需要描述自己的任务就能轻松上云的 Sky,还是很有前景的,或许是分布式计算的又一个里程碑。