这次实验课上布置了另外的任务,即实现 MTFQ 以及工作集算法。
在实验过程中,发现 ucore 并没有对用户进程 swap 提供支持,因此加入了一些修正。
练习 1 完成 ucore 文件系统读文件操作的实现
// 处理一开始的块
if ((blkoff = offset % SFS_BLKSIZE) != 0 ) {
if (nblks != 0) {
// 不在一块里
size = SFS_BLKSIZE - blkoff;
} else {
// 在一块里
size = endpos - offset;
}
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0) {
goto out;
}
if ((ret = sfs_buf_op(sfs, buf, size, ino, blkoff)) != 0) {
goto out;
}
alen += size;
if (nblks == 0) {
goto out;
}
buf += size, blkno ++, nblks --;
}
size = SFS_BLKSIZE;
// 循环处理中间的块
while (nblks != 0) {
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0) {
goto out;
}
if ((ret = sfs_block_op(sfs, buf, ino, 1)) != 0) {
goto out;
}
alen += size, buf += size, blkno ++, nblks --;
}
// 处理最后的块
if ((size = endpos % SFS_BLKSIZE) != 0) {
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0) {
goto out;
}
if ((ret = sfs_buf_op(sfs, buf, size, ino, 0)) != 0) {
goto out;
}
alen += size;
}在读写文件系统的时候,只能按块读写,但是有可能需要读取的文件内容开始和结束偏移没有对齐到块,所以需要单独处理。而 sfs_buf_op 其实内部实现也是按块读取,只是在写入 buf 的时候丢弃一部分数据而已。
在处理开始块的时候,没有对齐的时候有两种情况:
- 开始和结束地址都在一块里:这时候需要读取的
size = endpos - offset - 开始和结束地址不在一块里:这时候需要读取的
size = SFS_BLKSIZE - blkoff
然后就是按块读写中间块,最后读写结束的位置可能也没有对齐到块上,这时候只有一种情况,那就是 size = endpos % SFS_BLKSIZE。
在读写块的时候,首先需要根据 inode 块号获取对应的物理块号,然后调用 sfs_block_op 或者 sfs_buf_op 去操作物理磁盘。操作成功后更新 alen,buf,blkno 和 nblks。
练习 2 完成基于文件系统的执行程序机制的实现
/* (1) create a new mm for current process
* (2) create a new PDT, and mm->pgdir= kernel virtual addr of PDT
* (3) copy TEXT/DATA/BSS parts in binary to memory space of process
* (3.1) read raw data content in file and resolve elfhdr
* (3.2) read raw data content in file and resolve proghdr based on info in elfhdr
* (3.3) call mm_map to build vma related to TEXT/DATA
* (3.4) callpgdir_alloc_page to allocate page for TEXT/DATA, read contents in file
* and copy them into the new allocated pages
* (3.5) callpgdir_alloc_page to allocate pages for BSS, memset zero in these pages
* (4) call mm_map to setup user stack, and put parameters into user stack
* (5) setup current process's mm, cr3, reset pgidr (using lcr3 MARCO)
* (6) setup uargc and uargv in user stacks
* (7) setup trapframe for user environment
* (8) if up steps failed, you should cleanup the env.
*/
int ret = -E_NO_MEM;
struct mm_struct *mm;
if ((mm = mm_create()) == NULL) {
goto bad_mm;
}
if (setup_pgdir(mm) != 0) {
goto bad_pgdir;
}
struct Page *page;
struct elfhdr __elf, *elf = &__elf;
if ((ret = load_icode_read(fd, elf,sizeof(struct elfhdr), 0)) != 0) {
goto bad_elf;
}
if (elf->e_magic != ELF_MAGIC) {
ret = -E_INVAL_ELF;
goto bad_elf;
}
struct proghdr __ph, *ph = &__ph;
uint32_t vm_flags, perm, phnum;
for (phnum = 0; phnum < elf->e_phnum; ++phnum) {
off_t phoff = elf->e_phoff + sizeof(struct proghdr) * phnum;
if ((ret = load_icode_read(fd, ph, sizeof(struct proghdr), phoff)) != 0) {
goto bad_cleanup_mmap;
}
// 这一段不需要加载
if (ph->p_type != ELF_PT_LOAD || ph->p_filesz == 0) {
continue ;
}
if (ph->p_filesz > ph->p_memsz) {
ret = -E_INVAL_ELF;
goto bad_cleanup_mmap;
}
vm_flags = 0, perm = PTE_U;
if (ph->p_flags & ELF_PF_X) vm_flags |= VM_EXEC;
if (ph->p_flags & ELF_PF_W) vm_flags |= VM_WRITE;
if (ph->p_flags & ELF_PF_R) vm_flags |= VM_READ;
if (vm_flags & VM_WRITE) perm |= PTE_W;
if ((ret = mm_map(mm, ph->p_va, ph->p_memsz, vm_flags, NULL)) != 0) {
goto bad_cleanup_mmap;
}
off_t offset = ph->p_offset;
size_t off, size;
uintptr_t start = ph->p_va, end = ph->p_va + ph->p_filesz, la = ROUNDDOWN(start, PGSIZE);
ret = -E_NO_MEM;
while (start < end) {
if ((page = pgdir_alloc_page(mm->pgdir, la, perm)) == NULL) {
ret = -E_NO_MEM;
goto bad_cleanup_mmap;
}
off = start - la, size = PGSIZE - off, la += PGSIZE;
if (end < la) {
size -= la - end;
}
if ((ret = load_icode_read(fd, page2kva(page) + off, size, offset)) != 0) {
goto bad_cleanup_mmap;
}
start += size, offset += size;
}
end = ph->p_va + ph->p_memsz;
if (start < la) {
if (start == end) {
continue ;
}
off = start + PGSIZE - la, size = PGSIZE - off;
if (end < la) {
size -= la - end;
}
memset(page2kva(page) + off, 0, size);
start += size;
assert((end < la && start == end) || (end >= la && start == la));
}
while (start < end) {
if ((page = pgdir_alloc_page(mm->pgdir, la, perm)) == NULL) {
ret = -E_NO_MEM;
goto bad_cleanup_mmap;
}
off = start - la, size = PGSIZE - off, la += PGSIZE;
if (end < la) {
size -= la - end;
}
memset(page2kva(page) + off, 0, size);
start += size;
}
}
sysfile_close(fd);
vm_flags = VM_READ | VM_WRITE | VM_STACK;
if ((ret = mm_map(mm, USTACKTOP - USTACKSIZE, USTACKSIZE, vm_flags, NULL)) != 0) {
goto bad_cleanup_mmap;
}
mm_count_inc(mm);
current->mm = mm;
current->cr3 = PADDR(mm->pgdir);
lcr3(PADDR(mm->pgdir));
//setup argc, argv
uint32_t argv_size=0, i;
for (i = 0; i < argc; i ++) {
argv_size += strnlen(kargv[i],EXEC_MAX_ARG_LEN + 1)+1;
}
uintptr_t stacktop = USTACKTOP - (argv_size/sizeof(long)+1)*sizeof(long);
char** uargv=(char **)(stacktop - argc * sizeof(char *));
argv_size = 0;
for (i = 0; i < argc; i ++) {
uargv[i] = strcpy((char *)(stacktop + argv_size ), kargv[i]);
argv_size += strnlen(kargv[i],EXEC_MAX_ARG_LEN + 1)+1;
}
stacktop = (uintptr_t)uargv - sizeof(int);
*(int *)stacktop = argc;
struct trapframe *tf = current->tf;
memset(tf, 0, sizeof(struct trapframe));
tf->tf_cs = USER_CS;
tf->tf_ds = tf->tf_es = tf->tf_ss = USER_DS;
tf->tf_esp = stacktop;
tf->tf_eip = elf->e_entry;
tf->tf_eflags = FL_IF;
ret = 0;
out:
return ret;
bad_cleanup_mmap:
exit_mmap(mm);
bad_elf:
put_pgdir(mm);
bad_pgdir:
mm_destroy(mm);
bad_mm:
goto out;
}在 execve 中,由于程序变为从文件系统中加载,需要完全重写,但是思路很简单。
- 调用
create_mm为程序分配虚拟内存管理结构体。 - 调用
setup_pgdir为程序建立页表。 - 从
fd中调用load_icode_read从文件系统中读取elf文件头。 - 根据
elfhdr中的信息,遍历所有proghdr,根据proghdr中的信息,建立连续的虚拟内存映射,并设置对应的权限(读/写/执行),并使用mm_map将虚拟内存插入到程序的虚拟内存管理结构体中。 - 针对每一程序段,需要分配物理页面,然后将该程序段中的文件内容(大小为
ph_filesz)拷贝到内存中。而ph_memsz标识了这一段实际占用内存空间的大小,应该有ph_filesz <= ph_memsz,在拷贝完文件内容之后,需要将剩下的空间置为 0,这时候有可能发生没有对齐的情况,需要特殊处理。 - 处理完
elf中的所有程序段之后,开始初始化用户栈,所有用户栈顶地址都是USTACKTOP,用户栈大小为USTACKSIZE,这里只需要调用mm_map建立内存映射即可,在发生缺页的时候会自动分配物理页。也可以先手动用pgdir_alloc_page事先分配好物理页。 - 此时虚拟内存已经设置完毕,将
mm赋值给当前进程,然后调用lcr3使新的页表生效。 - 这时候开始设置
argc和argv,将运行参数拷贝到用户栈上。 - 最后设置
trapframe使操作系统从中断返回后能进入用户态从elf入口执行用户程序。
练习 3 多级反馈队列调度算法
多级反馈队列调度算法是在 Round Robin 算法基础上增加了多个运行队列,所以首先对 struct run_queue 做一下改动,分配多个级别的调度列表。MULTI_QUEUE_NUM = 6 是指有多少级调度队列。
#define MULTI_QUEUE_NUM 6
struct run_queue {
// ...
list_entry_t multi_run_list[MULTI_QUEUE_NUM];
};然后需要在进程控制块中新增一个字段表明该进程处于哪个队列:
struct proc_struct {
// ...
uint32_t queue_level;
};每个进程创建时,queue_level 初始化为 0。queue_level 越大,表明优先级越低。
#include <defs.h>
#include <list.h>
#include <proc.h>
#include <assert.h>
#include <default_sched.h>
static void
multi_init(struct run_queue *rq) {
for (int i = 0; i < MULTI_QUEUE_NUM; ++i) {
list_init(&(rq->multi_run_list[i]));
}
rq->proc_num = 0;
rq->multi_queue_q = rq->max_time_slice;
}
static void
multi_enqueue(struct run_queue *rq, struct proc_struct *proc) {
assert(list_empty(&(proc->run_link)));
if (proc->time_slice == 0 && proc->queue_level + 1 < MULTI_QUEUE_NUM) {
++proc->queue_level;
}
proc->time_slice = rq->multi_queue_q << proc->queue_level;
list_add_before(&(rq->multi_run_list[proc->queue_level]), &(proc->run_link));
proc->rq = rq;
rq->proc_num ++;
}
static void
multi_dequeue(struct run_queue *rq, struct proc_struct *proc) {
assert(!list_empty(&(proc->run_link)) && proc->rq == rq);
list_del_init(&(proc->run_link));
rq->proc_num --;
}
static struct proc_struct *
multi_pick_next(struct run_queue *rq) {
for (int i = 0; i < MULTI_QUEUE_NUM; ++i) {
list_entry_t *le = list_next(&(rq->multi_run_list[i]));
if (le != &(rq->multi_run_list[i])) {
return le2proc(le, run_link);
}
}
return NULL;
}
static void
multi_proc_tick(struct run_queue *rq, struct proc_struct *proc) {
if (proc->time_slice > 0) {
proc->time_slice --;
}
if (proc->time_slice == 0) {
proc->need_resched = 1;
}
}
struct sched_class default_sched_class = {
.name = "multi_scheduler",
.init = multi_init,
.enqueue = multi_enqueue,
.dequeue = multi_dequeue,
.pick_next = multi_pick_next,
.proc_tick = multi_proc_tick,
};上面是 MTFQ 的实现,在初始化的时候,需要对每一级队列初始化。
在进程入队的时候,需要先判断该进程之前的时间片是否用完了,如果用完了,说明这个进程需要更多的 CPU 时间,因此需要调度进入下一级队列,然后根据队列来设置进程时间片。如果进程已经在最后一级队列,就不再往下调。
在选择下一个需要执行的进程的时候,从优先级高的队列开始遍历,如果在高优先级的队列中没有需要调度的进程,才在低优先级的队列中寻找进程。
进程的出队和时间片减少的算法和 RR 算法一样。
练习 4 修改虚拟存储中的页面置换算法
在 load_icode 函数里,预先分配三页物理帧给进程:
if ((ret = mm_map(mm, USTACKTOP - USTACKSIZE, USTACKSIZE, vm_flags, NULL)) != 0) {
goto bad_cleanup_mmap;
}
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-2*PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-3*PGSIZE , PTE_USER) != NULL);在进程控制块中,需要加入一个字段,用来记录进程的缺页次数:
struct proc_struct {
// ...
uint32_t pgfault;
};然后在 do_pgfault 函数中更新这个值:
int
do_pgfault(struct mm_struct *mm, uint32_t error_code, uintptr_t addr) {
// ...
++current->pgfault;
ret = 0;
failed:
return ret;
}static int _clock_init_mm(struct mm_struct *mm) {
mm->sm_priv = NULL;
return 0;
}
static int _clock_map_swappable(struct mm_struct *mm, uintptr_t addr,
struct Page *page, int tick) {
list_entry_t *head = (list_entry_t *)mm->sm_priv;
list_entry_t *entry = &(page->pra_page_link);
assert(entry != NULL);
if (head == NULL) {
list_init(entry);
mm->sm_priv = entry;
} else {
list_add_before(head, entry);
}
return 0;
}
static int _clock_swap_out_victim(struct mm_struct *mm, struct Page **ptr_page,
int in_tick) {
struct proc_struct* m_proc = NULL;
for (list_entry_t *le = list_next(&proc_list); le != &proc_list; le = list_next(le)) {
struct proc_struct *proc = le2proc(le, list_link);
assert(proc != NULL);
if (!proc->mm || !proc->mm->sm_priv) continue;
if (!m_proc || proc->pgfault < m_proc->pgfault) {
m_proc = proc;
}
}
if (m_proc) mm = m_proc->mm, cprintf("[swap_out_victim] mm = %p, pid = %d\n", mm, m_proc->pid);
list_entry_t *head = (list_entry_t *)mm->sm_priv;
list_entry_t *p = head, *victim = NULL;
do {
pte_t *ptep =
get_pte(mm->pgdir, le2page(p, pra_page_link)->pra_vaddr, 0);
// not accessed and not dirty
if (!(*ptep & PTE_A) && !(*ptep & PTE_D)) {
victim = p;
break;
}
p = list_next(p);
} while (p != head);
if (!victim) do {
pte_t *ptep =
get_pte(mm->pgdir, le2page(p, pra_page_link)->pra_vaddr, 0);
// not accessed and dirty
if (!(*ptep & PTE_A) && (*ptep & PTE_D)) {
victim = p;
break;
}
*ptep &= ~PTE_A;
tlb_invalidate(mm->pgdir, le2page(p, pra_page_link)->pra_vaddr);
p = list_next(p);
} while (p != head);
if (!victim) do {
pte_t *ptep =
get_pte(mm->pgdir, le2page(p, pra_page_link)->pra_vaddr, 0);
// not accessed and not dirty
if (!(*ptep & PTE_A) && !(*ptep & PTE_D)) {
victim = p;
break;
}
p = list_next(p);
} while (p != head);
if (!victim) do {
pte_t *ptep =
get_pte(mm->pgdir, le2page(p, pra_page_link)->pra_vaddr, 0);
// not accessed and dirty
if (!(*ptep & PTE_A) && (*ptep & PTE_D)) {
victim = p;
break;
}
*ptep &= ~PTE_A;
tlb_invalidate(mm->pgdir, le2page(p, pra_page_link)->pra_vaddr);
p = list_next(p);
} while (p != head);
if (list_empty(victim)) {
mm->sm_priv = NULL;
} else {
mm->sm_priv = list_next(victim);
list_del(victim);
}
*ptr_page = le2page(victim, pra_page_link);
return 0;
}
在选择需要被换出的页的时候,首先遍历进程列表,找到有页可换的进程中缺页次数最少的进程,然后开始执行 Extended Clock PRA。
在普通的 Clock PRA 算法里,只考虑了页面是否被访问,但是没有考虑页面是否脏页,显然脏页换出的代价比非脏页更大,因此在 Extended Clock PRA 里,还要优先选择不是脏页的页面。
在 Extended Clock PRA 中,插入和 FIFO PRA 一样,直接插入到链表尾部。在选择需要被换出的页面的时候,从上一次被换出页的下一页开始扫描,需要至多四趟扫描:
- 寻找没被访问 (
PTE_A == 0) 而且没被修改的非脏页 (PTE_D == 0),其中PTE_A和PTE_D都是 CPU 硬件置位的。 - 寻找没被访问 (
PTE_A == 0) 的脏页 (PTE_D == 1),并且将途中扫描到的页面的PTE_A都修改为 0 - 重复 1
- 重复 2
为了实现定时清空缺页次数统计的要求,需要在定时器中断中调用 Swap Manager 的函数:
case IRQ_OFFSET + IRQ_TIMER:
++ticks;
assert(current != NULL);
if (ticks % 1000 == 0) { // 每 1000 ticks 调用一次
swap_tick_event(NULL);
}
run_timer_list();
break;
在 Swap Manager 中清空:
static int _clock_tick_event(struct mm_struct *mm) {
for (list_entry_t *le = list_next(&proc_list); le != &proc_list; le = list_next(le)) {
struct proc_struct *proc = le2proc(le, list_link);
proc->pgfault = 0;
}
return 0;
}
需要注意的是,每个进程都有自己的交换页面队列。
实验思考
在 ucore 中,其实并没有对用户进程 swap 做任何处理。由于 swap 的偏移量由虚拟地址简单计算得出,因此对于用户栈而言,其地址过大,导致 swap 中找不到位置存放。经过计算,如果不修改用户栈顶地址,则需要 22 * 128 MB = 2.75 GB 的 swap 空间(在 Makefile 中调整 dd 命令的 count 参数);如果需要避免过大的 swap 占用,可以简单将用户栈顶地址调小。
但是这样会有另外一个问题:由于每个进程的虚拟地址都是一样的,因此不同进程的同一地址的页面会交换到同一个地方,造成错误。
使用地址来计算 swap 偏移有根本上的错误,无论是使用虚拟地址还是物理地址,因为同一个地址都有可能被多个进程同时使用。因此,需要另外的机制分配 swap 空间。
为了同时解决以上两个问题,简单起见可以使用 bitmap 来分配 swap 空间。在 swapfs 中分配一个 bitmap 用来记录 swap 分区中已被使用的区域,在需要换出页面的时候申请一块。在换入页面的时候释放一块。
static int *swap_bitmap;
static int free_swap;
void
swapfs_init(void) {
static_assert((PGSIZE % SECTSIZE) == 0);
if (!ide_device_valid(SWAP_DEV_NO)) {
panic("swap fs isn't available.\n");
}
max_swap_offset = ide_device_size(SWAP_DEV_NO) / (PGSIZE / SECTSIZE);
free_swap = max_swap_offset;
swap_bitmap = kmalloc(max_swap_offset / 8);
memset(swap_bitmap, 0, free_swap);
--free_swap;
cprintf("[swapfs_init] free_swap = %d\n", free_swap);
}
swap_entry_t get_swap_entry() {
swap_entry_t entry;
if (!free_swap) {
panic("no free swap space!!!\n");
}
for (int i = 1; i < max_swap_offset; ++i) {
if (!test_bit(i, swap_bitmap)) {
set_bit(i, swap_bitmap);
--free_swap;
entry = i << 8;
return entry;
}
}
return 0;
}
void free_swap_entry(swap_entry_t entry) {
clear_bit(swap_offset(entry), swap_bitmap);
++free_swap;
}
这里 bitmap 分配了 1024 个 int 的大小,也就是 4 * 8 * 1024 = 32768 个比特位,有 32768 页可用来 swap,这是因为 swap.img 有 128 MB,每页大小 4 KB,因此有 32768 页可以交换。
然后修改 swap_in 和 swap_out 函数:
int
swap_out(struct mm_struct *mm, int n, int in_tick)
{
int i;
for (i = 0; i != n; ++ i)
{
uintptr_t v;
struct Page *page;
// cprintf("i %d, SWAP: call swap_out_victim\n",i);
int r = sm->swap_out_victim(mm, &page, in_tick);
if (r != 0) {
cprintf("i %d, swap_out: call swap_out_victim failed\n",i);
break;
}
//assert(!PageReserved(page));
// cprintf("SWAP: choose victim page 0x%08x\n", page);
v=page->pra_vaddr;
pte_t *ptep = get_pte(mm->pgdir, v, 0);
assert((*ptep & PTE_P) != 0);
swap_entry_t entry = get_swap_entry(); // 改为从分配器中获取,不是地址
if (swapfs_write(entry , page) != 0) {
cprintf("SWAP: failed to save\n");
sm->map_swappable(mm, v, page, 0);
continue;
}
else {
*ptep = entry;
free_page(page);
}
tlb_invalidate(mm->pgdir, v);
}
return i;
}
int
swap_in(struct mm_struct *mm, uintptr_t addr, struct Page **ptr_result)
{
struct Page *result = alloc_page();
assert(result!=NULL);
pte_t *ptep = get_pte(mm->pgdir, addr, 0);
int r;
if ((r = swapfs_read((*ptep), result)) != 0)
{
assert(r!=0);
}
free_swap_entry(*ptep); // 释放 swap 空间
*ptr_result=result;
return 0;
}
关于三个物理帧的要求,也可以理解为整个进程包括代码段、BSS 段只能使用 3 个物理帧。在这种情况下,需要统计每个进程使用的物理页面才能进行限制。同时,由于在 fork 的时候,有可能有一部分的页面在 swap 分区上,从而在 copy_range 的时候不会被拷贝,需要改造 copy_range 复制处于 swap 分区上的页面。
int
copy_range(pde_t *to, pde_t *from, uintptr_t start, uintptr_t end, bool share) {
assert(start % PGSIZE == 0 && end % PGSIZE == 0);
assert(USER_ACCESS(start, end));
// copy content by page unit.
do {
//call get_pte to find process A's pte according to the addr start
pte_t *ptep = get_pte(from, start, 0), *nptep;
if (ptep == NULL) {
start = ROUNDDOWN(start + PTSIZE, PTSIZE);
continue ;
}
//call get_pte to find process B's pte according to the addr start. If pte is NULL, just alloc a PT
if (*ptep & PTE_P) {
// ....
} else {
if ((nptep = get_pte(to, start, 1)) == NULL) {
return -E_NO_MEM;
}
*nptep = *ptep;
if (*nptep != 0) {
// need to copy swap
struct Page* page = alloc_page();
swapfs_read(*nptep, page);
swap_entry_t entry = get_swap_entry();
swapfs_write(entry, page);
*nptep = entry;
free_page(page);
}
}
start += PGSIZE;
} while (start != 0 && start < end);
return 0;
}
最后,在进程退出的时候,也需要删除其所占用的 swap 空间。
static inline void
page_remove_pte(pde_t *pgdir, uintptr_t la, pte_t *ptep) {
if (*ptep & PTE_P) {
struct Page *page = pte2page(*ptep);
if (page_ref_dec(page) == 0) {
free_page(page);
}
*ptep = 0;
tlb_invalidate(pgdir, la);
} else {
// this is a swap page
free_swap_entry(*ptep);
*ptep = 0;
tlb_invalidate(pgdir, la);
}
}
为了统计使用物理帧的情况,需要在 struct mm_struct 中增加字段,并在分配页和释放页的时候同步更新,并且在超出使用限制的时候将多余的页面交换出去,从而达到限制每个进程的页面数的目的(用来测试交换功能,此时每个进程都以为内存只有三页物理帧可以用)。
struct mm_struct {
list_entry_t mmap_list; // linear list link which sorted by start addr of vma
struct vma_struct *mmap_cache; // current accessed vma, used for speed purpose
pde_t *pgdir; // the PDT of these vma
int map_count; // the count of these vma
void *sm_priv; // the private data for swap manager
int mm_count; // the number of process which shared the mm
semaphore_t mm_sem; // mutex for using dup_mmap fun to duplicate the mm
int locked_by; // the lock owner process's pid
int phys_count; // physical pages allocated to the mm
};
在申请新物理页的时候需要对 swap 信息和内存限制更新:
struct Page *
pgdir_alloc_page(pde_t *pgdir, uintptr_t la, uint32_t perm, struct mm_struct *mm) {
struct Page *page = alloc_page();
if (page != NULL) {
if (page_insert(pgdir, page, la, perm) != 0) {
free_page(page);
return NULL;
}
if (swap_init_ok){
if(check_mm_struct!=NULL) {
swap_map_swappable(check_mm_struct, la, page, 0);
page->pra_vaddr=la;
assert(page_ref(page) == 1);
//cprintf("get No. %d page: pra_vaddr %x, pra_link.prev %x, pra_link_next %x in pgdir_alloc_page\n", (page-pages), page->pra_vaddr,page->pra_page_link.prev, page->pra_page_link.next);
}
else if (mm) { // 统计物理页
swap_map_swappable(mm, la, page, 0);
page->pra_vaddr=la;
mm->phys_count++;
assert(page_ref(page) == 1);
}
}
}
return page;
}
检查物理页是否超出限制:
void
check_phys_page(struct mm_struct *mm) {
if (!mm) return;
if (MAX_PHYS_PAGE_PER_PROC && mm->phys_count == MAX_PHYS_PAGE_PER_PROC) {
swap_out(mm, 1, 1);
--mm->phys_count;
}
}
为了检查限制物理页的程序是否正确,编写以下程序进行大量内存使用的读写:
#include <ulib.h>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define ARRSIZE 100000
static int arr[ARRSIZE];
int
main(void) {
cprintf("This program will test working set alg...\n");
cprintf("Global arr size = %d\n", ARRSIZE);
cprintf("!!!!! You should see many page faults !!!!!\n");
for (int i = 0; i < ARRSIZE; ++i) {
arr[i] = i;
}
cprintf("!!!!! There should be few page faults !!!!!\n");
for (int i = 0; i < ARRSIZE; ++i) {
arr[i % 256] = i;
}
cprintf("finish...\n");
}
前半部分读写范围大,在物理页限制较少的时候应该会产生大量缺页以及大量页面交换,后半部分读写范围不足一页,应该极少出现缺页。
测试结果发现确实符合预期: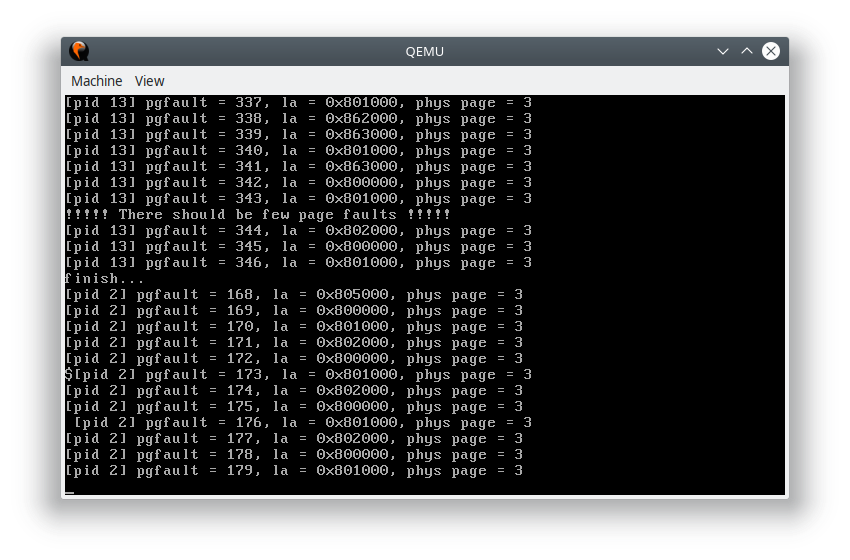
可以看到每个进程使用的物理页帧都被限制在三页以内,因此会出现大量的缺页异常,而在 workset 程序中,前半部分产生的缺页异常远远大于后半部分。由于代码段和 bss 段也被限制了,因此在程序执行过程中,也会出现大量的缺页异常,用来交换代码。