目录
之前学习了怎么使用 PyTorch 进行分布式训练,不过,手动计算参数启动进程还是比较麻烦的。Berkeley 的 RISELab 开发了 Ray 这个框架来简化分布式计算程序的编写。Ray 有以下几个优点:
- 支持在多种云平台一键部署集群
- 支持 Autoscaling,可以节省成本
- 支持多种深度学习框架,比如 PyTorch、TensorFlow
通过 Ray 统一的编程 API,写好的程序既可以在本地集群跑,本地集群资源紧张的时候也可以直接放到云端跑,不需要改代码,集群管理和调度都不需要我们自己操心。同时,Ray 还提供了调参库,等模型迭代成熟之后可以直接使用 Ray Tune 进行超参搜索,不需要自己写调参脚本了。
安装 Ray
安装 Ray 很简单,只需要在每台服务器都执行
pip install -U ray "ray[default]"启动 Ray
Ray 采用了中心化的管理模型,分为头节点(Head Node)和工作节点(Worker Node)。头节点负责资源调度、数据分发以及用户交互等,工作节点会主动连接到头节点接受任务并执行。所以,在启动不同节点的时候需要的命令不一样。
启动头节点
首先,任选一台服务器作为头节点,然后执行命令:
ray start --head --node-ip-address 10.0.0.1 --port=6379 --redis-password=123 --dashboard-host=0.0.0.0其中,--head 表示这是一个头节点,--node-ip-address 应该换成机器的真实 IP,不可以使用 127.0.0.1,接下来的两个参数则是指定了 Redis(用于数据交换的 KV 内存数据库)的启动选项,选择一个没有被占用的端口即可,密码可以自选。--dashboard-host 则是指定了 Ray 的监控面板应该监听哪个地址,默认监听的是 127.0.0.1,一般来说我们都不会在服务器上面开桌面,填 0.0.0.0 可以让我们用服务器的任何一个 IP 访问监控界面。
执行命令之后应该可以看到以下输出:
Local node IP: 10.0.0.1
2021-05-26 11:04:21,084 INFO services.py:1267 -- View the Ray dashboard at http://0.0.0.0:8265
--------------------
Ray runtime started.
--------------------
Next steps
To connect to this Ray runtime from another node, run
ray start --address='10.0.0.1:6379' --redis-password='123'
Alternatively, use the following Python code:
import ray
ray.init(address='auto', _redis_password='123')
If connection fails, check your firewall settings and network configuration.
To terminate the Ray runtime, run
ray stop启动工作节点
然后,在除了头节点以外的服务器上,复制粘贴执行上面输出的命令。
ray start --address='10.0.0.1:6379' --redis-password='123'成功应该可以看到以下输出:
Local node IP: 10.0.0.2
--------------------
Ray runtime started.
--------------------
To terminate the Ray runtime, run
ray stop说明工作节点成功连接到头节点了。
查看监控界面
头节点的输出中的
Local node IP: 10.0.0.1
2021-05-26 11:04:21,084 INFO services.py:1267 -- View the Ray dashboard at http://0.0.0.0:8265显示了监控界面的监听端口,这里是 8265,将 0.0.0.0 换成你的服务器 IP,然后打开网址,就能看到 Ray 的监控界面了。
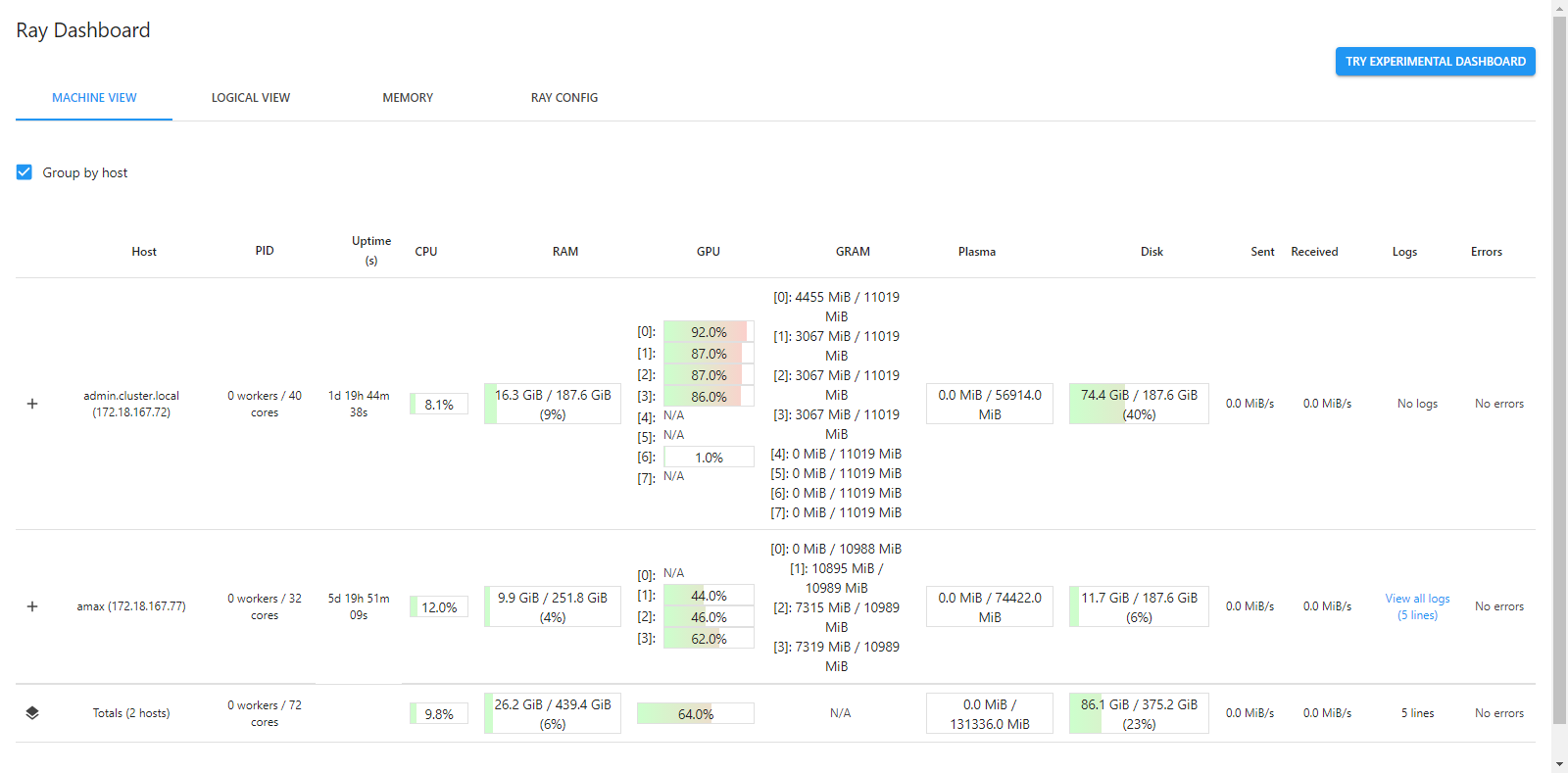
监控界面主要显示的是机器的资源情况还有任务执行情况。
用 Ray Tune 自动搜索超参训练模型
使用 Trainable 包装训练过程
Ray Tune 提供了几种方法将训练过程包装起来。首先是最基础的 tune.Trainable,这个类要求我们实现四个方法:
from ray import tune
class MNISTTrainable(tune.Trainable):
def setup(self, config):
pass
def step(self):
pass
def save_checkpoint(self, checkpoint_dir):
pass
def load_checkpoint(self, checkpoint_path):
pass首先,在模型训练开始前,Ray 会调用 setup 函数,这个函数里,我们需要做初始化的工作,比如加载模型和数据集以及设置优化器等,另外,训练的超参数也会从 config 中传进来,在这个函数读取并保存到对象属性里即可。需要注意的是,如果涉及到数据集的下载等,需要注意多进程文件读写的同步。
from ray.tune.examples.mnist_pytorch import (train, test, get_data_loaders,
ConvNet)
def setup(self, config):
use_cuda = config.get("use_gpu") and torch.cuda.is_available()
self.device = torch.device("cuda" if use_cuda else "cpu")
self.train_loader, self.test_loader = get_data_loaders()
self.model = ConvNet().to(self.device)
self.optimizer = optim.SGD(
self.model.parameters(),
lr=config.get("lr", 0.01),
momentum=config.get("momentum", 0.9))然后,Ray 会循环调用 step 函数,在 step 的最后,应该返回一个字典,用来告诉 Ray 这次迭代的指标:
def step(self):
train(self.model, self.optimizer, self.train_loader, device=self.device)
acc = test(self.model, self.test_loader, self.device)
return {"mean_accuracy": acc}后面两个参数则是为了恢复训练而设计的,save_checkpoint 函数由 Ray 定期调用,在这个函数里,应该将训练的中间状态保存到 checkpoint_dir 指定的位置,并且返回保存后的路径。注意这里只能保存一个文件,保存的时候可以用 tuple 的方式将模型参数和优化器状态保存到文件里。
def save_checkpoint(self, checkpoint_dir):
checkpoint_path = os.path.join(checkpoint_dir, "checkpoint.bin")
torch.save((self.model.state_dict(), self.optimizer.state_dict()), checkpoint_path)
return checkpoint_pathload_checkpoint 则顾名思义,只需要加载传进来的 checkpoint_path 文件即可 :
def load_checkpoint(self, checkpoint_path):
model, optimizer = torch.load(checkpoint_path)
self.model.load_state_dict(model)
self.optimizer.load_state_dict(optimizer)调用 Ray Tune 进行训练
实现了四个函数之后,就可以将我们的类交给 Ray Tune 进行调度运行,运行的方法非常简单。主函数只需要初始化 Ray 环境,然后调用 tune.run 即可。
from ray.tune.schedulers import ASHAScheduler
from ray.tune import CLIReporter
if __name__ == "__main__":
# 初始化 Ray 集群
ray.init(address='auto')
# 开始搜索超参
sched = ASHAScheduler(metric="mean_accuracy", mode="max")
reporter = CLIReporter()
analysis = tune.run(MNISTTrainable,
scheduler=sched,
progress_reporter=reporter,
stop={"mean_accuracy": 0.99,
"training_iteration": 100},
resources_per_trial={"cpu": 2, "gpu": 1},
num_samples=128,
config={"lr": tune.uniform(0.001, 1.0),
"momentum": tune.uniform(0.1, 0.9),
"use_gpu": True})
# 保存实验结果
analysis.results_df.to_csv("result.csv")
# 获得最佳参数
print("Best config is:", analysis.get_best_config(metric="mean_accuracy", mode="max"))其中,scheduler 参数表示超参搜索的策略,有一些调度器可以提前终止表现一般的实验,节省资源给其他实验,同时也节省了搜索时间。具体有哪些调度器可以参考官方文档。
而 stop 指定了停止的标准,一般需要设置 training_iteration,表示最多调用几次 step 函数,其他可以按照自己的需要设置,设置的值需要是 step 会返回的。
progress_reporter 指定了实验进度如何反馈给用户,这里用了默认的 CLIReporter ,如果用 Jupyter Notebook,可以用 JupyterNotebookReporter。
resources_per_trial 则指定了分配多少资源给每个实验,默认是 1 个 CPU 和 0 个 GPU,如果不指定 GPU 数量的话,将无法使用 GPU 进行训练(CUDA_VISIBLE_DEVICES 会被设置成空值,即使服务器有 GPU 程序也会不认)。因为上面的示例没有写多卡代码,所以每个实验直接使用 1 个 GPU 即可。Ray 会尽可能调度多的实验一起跑,假如你有 8 个 GPU,那么会有 8 个实验同时进行。
num_samples 表示执行多少次实验,每一次实验,会将 config 里指定为随机分布的参数采样一遍。如果 config 里指定了 grid_search,那么同样的参数会被重复 num_samples 次。
# 会运行 9 个实验
tune.run(trainable, num_samples=1, config={
"x": tune.grid_search([1, 2, 3]),
"y": tune.grid_search([a, b, c])}
)
# 会运行 18 个实验
tune.run(trainable, num_samples=2, config={
"x": tune.grid_search([1, 2, 3]),
"y": tune.grid_search([a, b, c])}
)编写完主函数之后,保存脚本,在任意一个启动了 Ray 的服务器上运行你的脚本
python main.py应该可以看到输出:
2021-05-26 11:41:09,280 INFO worker.py:640 -- Connecting to existing Ray cluster at address: 10.0.0.1:6379说明成功连接到了 Ray 集群,训练过程中,应该可以看到类似的进度报告:
== Status ==
Memory usage on this node: 19.0/250.9 GiB
Using AsyncHyperBand: num_stopped=3
Bracket: Iter 64.000: None | Iter 16.000: None | Iter 4.000: 0.1129 | Iter 1.000: 0.1129
Resources requested: 20.0/112 CPUs, 16.0/16 GPUs, 0.0/689.53 GiB heap, 0.0/299.5 GiB objects (0.0/4.0 accelerator_type:V100)
Current best trial: 358bb_00006 with mean_accuracy=0.1174 and parameters={'lr': 0.00032010745937302484, 'momentum': 0.3077716737703313}
Result logdir: /home/ray/ray_results/TorchTrainable_2021-05-26_11-41-09
Number of trials: 32/32 (25 PENDING, 4 RUNNING, 3 TERMINATED)
+----------------------------+------------+--------------------+-------------+------------+--------+--------+------------------+---------------+---------+---------------+
| Trial name | status | loc | lr | momentum | acc | iter | total time (s) | num_samples | epoch | batch_count |
|----------------------------+------------+--------------------+-------------+------------+--------+--------+------------------+---------------+---------+---------------|
| TorchTrainable_358bb_00000 | RUNNING | 89.72.32.13:12113 | 0.00874452 | 0.652566 | 0.0829 | 6 | 50.2268 | 10000 | 6 | 40 |
| TorchTrainable_358bb_00003 | RUNNING | 89.72.32.24:283613 | 0.00380314 | 0.755093 | 0.1128 | 6 | 49.1289 | 10000 | 6 | 40 |
| TorchTrainable_358bb_00004 | RUNNING | 89.72.32.55:441696 | 0.000573206 | 0.531036 | 0.113 | 4 | 31.9356 | 10000 | 4 | 40 |
| TorchTrainable_358bb_00006 | RUNNING | 89.72.32.18:30118 | 0.000320107 | 0.307772 | 0.1174 | 3 | 23.9964 | 10000 | 3 | 40 |
| TorchTrainable_358bb_00007 | PENDING | | 0.000578684 | 0.826577 | | | | | | |
| TorchTrainable_358bb_00008 | PENDING | | 0.000104167 | 0.841208 | | | | | | |
| TorchTrainable_358bb_00009 | PENDING | | 0.00792254 | 0.419486 | | | | | | |
| TorchTrainable_358bb_00010 | PENDING | | 0.00238698 | 0.496603 | | | | | | |
| TorchTrainable_358bb_00011 | PENDING | | 0.00342996 | 0.611557 | | | | | | |
| TorchTrainable_358bb_00012 | PENDING | | 0.000662736 | 0.379733 | | | | | | |
| TorchTrainable_358bb_00013 | PENDING | | 0.000326747 | 0.835042 | | | | | | |
| TorchTrainable_358bb_00014 | PENDING | | 0.00234961 | 0.761008 | | | | | | |
| TorchTrainable_358bb_00015 | PENDING | | 0.00748315 | 0.234968 | | | | | | |
| TorchTrainable_358bb_00016 | PENDING | | 0.000121585 | 0.806935 | | | | | | |
| TorchTrainable_358bb_00017 | PENDING | | 0.00011588 | 0.578034 | | | | | | |
| TorchTrainable_358bb_00018 | PENDING | | 0.00218129 | 0.663069 | | | | | | |
| TorchTrainable_358bb_00019 | PENDING | | 0.000373483 | 0.726266 | | | | | | |
| TorchTrainable_358bb_00001 | TERMINATED | | 0.000819226 | 0.293562 | 0.0594 | 1 | 8.50461 | 10000 | 1 | 40 |
| TorchTrainable_358bb_00002 | TERMINATED | | 0.00035852 | 0.701368 | 0.0722 | 1 | 8.65457 | 10000 | 1 | 40 |
| TorchTrainable_358bb_00005 | TERMINATED | | 0.00253235 | 0.834568 | 0.0767 | 1 | 8.26594 | 10000 | 1 | 40 |
+----------------------------+------------+--------------------+-------------+------------+--------+--------+------------------+---------------+---------+---------------+
... 12 more trials not shown (12 PENDING)使用 TrainingOperator 包装训练过程
可以看到使用 tune.Trainable 的话,需要自己设置模型训练的初始化过程,需要自己封装多卡训练代码或者混合精度训练,如果没有特殊需求,可以使用 ray.util.sgd.torch 提供的 TrainingOperator。使用 TrainingOperator 可以不用自己操心 checkpoint 以及是否使用多卡等细节。
使用 TrainingOperator 和 Trainable 类似,需要我们重载几个方法。必须重载的只有 setup 方法。
class MNISTrainingOperator(TrainingOperator):
def setup(self, config):
train_loader, test_loader = get_data_loaders()
model = ConvNet()
optimizer = optim.SGD(model.parameters(), lr=config.get("lr", 1e-4), momentum=config.get("momentum", 0.9))
criterion = torch.nn.NLLLoss()
self.model, self.optimizer, self.criterion = self.register(models=model, optimizers=optimizer, criterion=criterion)
self.register_data(train_loader=train_loader, validation_loader=test_loader)在 setup 方法中,只需要做两件事:注册模型、注册数据加载器。而且,不用自己操心 DataParallel 之类的包装,也不需要操心 checkpoint 加载保存。甚至连训练循环都不需要自己写,当然大部分情况下还是需要自己重载的。
注册模型使用的是 self.register 方法,这个函数负责注册模型和优化器等,以便 Ray 分发模型参数。另外,如果需要自定义学习率的 scheduler,参数名是 schedulers。如果使用分布式训练,还可以使用 ddp_args={"find_unused_parameters": True} 来自定义 ddp 参数。如果使用混合精度训练,可以使用 apex_args={"opt_level": "O2"} 自定义 APEX 参数。
参数都可以传入数组,假如训练 GAN,models 就可以传 [generator, discriminator]。不过,假如 models 是数组,就必须重载 train_epoch 函数。
注册后,Ray 会自动使用 APEX 或者 DistributedDataParallel 包装模型,不需要我们自己包装。
register_data 负责注册数据加载器,同样的,Ray 会自动使用 DistributedRandomSampler 帮我们包装,不需要自己操心细节。
默认的情况下,TrainingOperator 的训练代码大概如下:
def train_epoch(self):
for idx, batch in enumerate(self.train_loader):
batch_info = {"batch_idx": idx, "global_step": global_step}
metrics = self.train_batch(batch, batch_info)
meter.update(metrics)
return meter.summary()
def train_batch(self, batch, batch_info):
*features, target = batch
features = [feature.to(self.device) for feature in features]
target = target.to(self.device)
output = model(*features)
loss = self.criterion(output, target)
return {"train_loss": loss, "num_samples": target.size(0)}当然,实际代码里会有其他的工作,比如更新 scheduler 还有一些统计工作。eval 的代码也大同小异,只是函数名字分别叫 validate 和 validate_batch。
如果要重写函数,记得 train_epoch 需要返回这个 epoch 的统计量字典。如果只重写 train_batch ,需要注意返回的字典一定要有 num_samples,代表这个 batch 有多少样本。
定义好 TrainingOperator 之后,用 Trainer 将 TrainingOperator 包装起来:
trainer = TorchTrainer(
training_operator_cls=MNISTrainingOperator,
num_workers=8,
num_cpus_per_worker=2,
use_gpu=True,
use_fp16=True,
config={"batch_size": 16}
)其中,num_workers 代表使用多少个进程训练,其他参数 num_cpus_per_worker 则顾名思义。如果有多个 worker,模型和加载器就会自动被 DistributedDataParallel 和 DistributedRandomSampler 包装,自动扩展到多卡训练。而 use_fp16 则指定是否使用 APEX 混合精度训练。
之后,只需要调用 trainer.train() 就能训练一个 epoch:
for i in range(num_epochs):
metrics = trainer.train()
val_metrics = trainer.validate()Trainer 本身不是一个可以直接传到 Ray Tune 的 Trainable,要想得到 Trainable,只需要执行
trainable = TorchTrainer.as_trainable(
training_operator_cls=MNISTrainingOperator,
num_workers=8,
num_cpus_per_worker=2,
use_gpu=True,
use_fp16=True,
config={"batch_size": 16}
)之后,参照上面的代码用 tune.run 执行这个 Trainable 就可以自动调参。
需要注意的是,使用这种方式调用 tune.run 的话,不需要也不可以指定 resources_per_trial,trainer 会有额外的方法自动计算所需要的资源传给 Ray Tune。