目录
啥是 Matrix
Matrix 是中山大学数据科学与计算机学院维护的一套用于编程教学的课程系统,具备布置作业、举办考试、线上评测等齐全的功能。
手工部署时代
在最原始的时代,我们写好一个 Web 应用之后,将代码拷贝到服务器上,然后将服务进程跑起来,访问一下端口是不是正常工作,就算部署好了。然而,每次发布新版本,我们都要重新上传代码,重新运行进程,还要手动装环境,那么,有没有办法摆脱这种原始的手工方式呢?在经历了各种失败和挫折之后,我们终于搭建起了自己的私有云服务,并将业务全部迁移到云上,实现了云上 Matrix。
应用集装箱:Docker
如果你上过操作系统、数据库、区块链等等等等需要实践的课程,你大概率会因为环境配置而感到挫折。不是报错少这个包就是报错软件版本不对,等好不容易把软件都装上了,终于能跑起来了,你已经被折腾个半死,不想做大作业了。更糟糕的是,要是两个课程的需要软件版本冲突了,你或许连退学的想法都有了。这时候,要是老师或者 TA 能给你一个 FTP 地址,让你下载一个虚拟机镜像,那就有如再生父母,救你于水深火热之中。
其实,在真正的 Web 服务发布的时候,也会面临着一样尴尬的问题。有时候在开发机上能正常运行,但是到了服务器上就是死活跑不起来,开发人员只好说 “But it works on my machine!”。又或许应用 A 需要包 X 的 1.0 版本,而应用 B 需要包 X 的 2.0 版本,而系统上只能同时存在一个版本,那就只能将两个应用部署在两个不同的系统上了。这显然会造成资源的浪费。尽管一些语言提供了虚拟环境管理工具,但有时更尴尬的是,有时候我们需要部署的应用忘记指定版本了,我们甚至不知道跑起来应该装什么软件包!
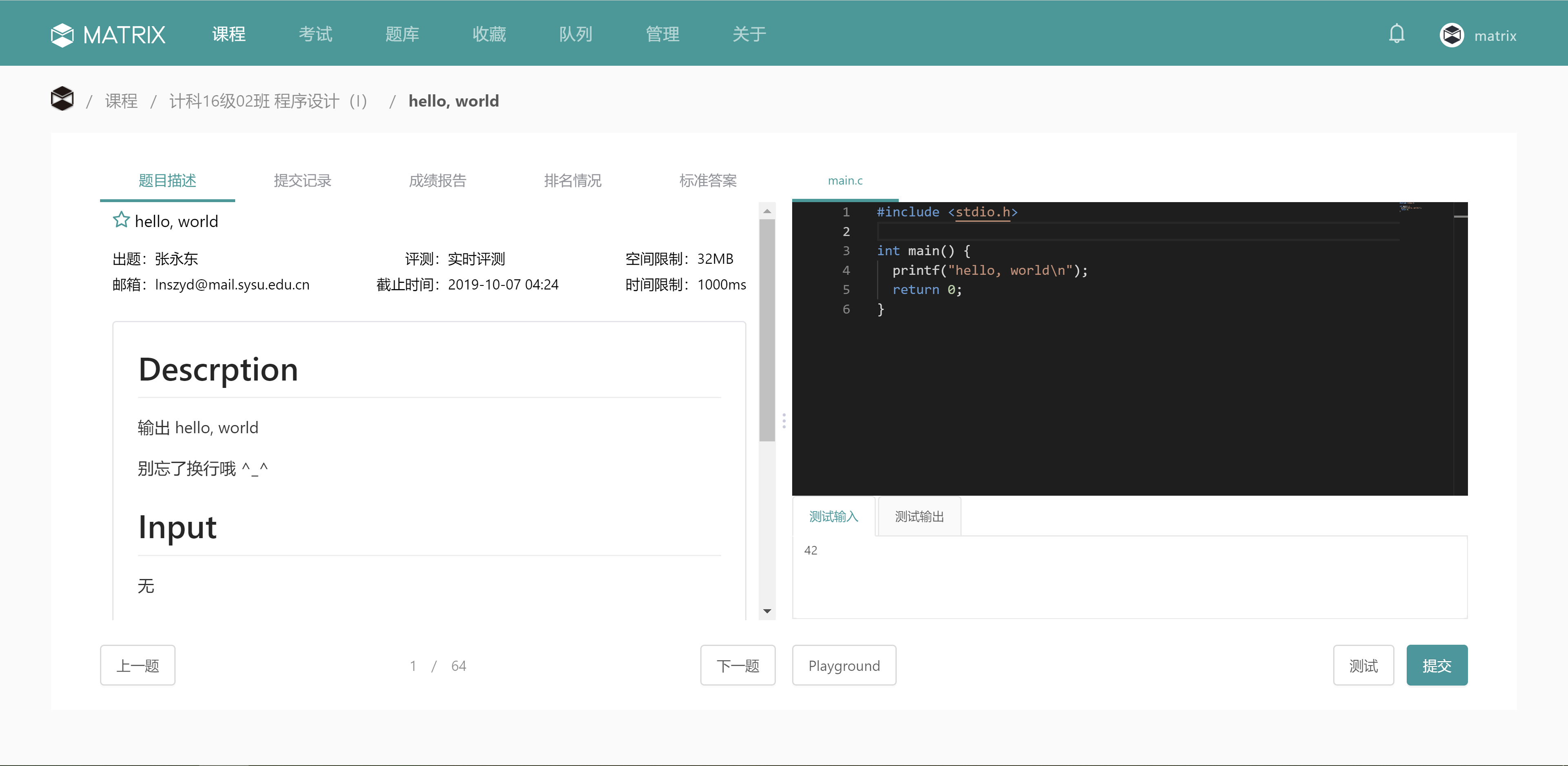
为了解决应用部署时的环境问题,以前人们就像我们上课一样,给不同的环境准备好一个虚拟机镜像,将依赖的软件统统打包起来,并且在虚拟机里调试运行正常,就可以发布到服务器上。而运维人员也不用再操心环境的干扰问题,直接把虚拟机镜像运行起来,就算部署成功了。然而,用过虚拟机镜像的都知道,一个虚拟机镜像动辄上 G,光是传输都要花上几分钟,解压之后占用空间还大,而且运行起来比较卡和占内存,因为虚拟机中的指令需要经过翻译,有较大的性能损耗。
显然,如果我们只是想跑起来一个网站,虚拟机就显得太“重”了。在 2008 年,Linux 推出了一个类似虚拟机的功能,称为 LXC(Linux Container)容器。容器的实现思想和 C++ 中的 namespace 如出一辙:在 C++ 里面,像 string、vector 等等都在 std 这个 namespace 里,而我们自己可以完全再新建一个叫 myns 的 namespace,在里面编写我们自己的 string 和 vector 而不用担心和标准库冲突。在 Linux 也一样,我们可以将网络、进程、文件系统等等按照 namespace 隔离,我们可以在 ns1 里运行依赖 X 1.0 版本的 A,在 ns2 里运行依赖 X 2.0 版本的 B,而两者互不干扰,就像各自运行在独立的系统中一样。而且我们也能像虚拟机一样,随时启动、暂停、停止容器。但其实它们都运行在同一个主机上,使用着同一个内核,读写着同一块硬盘!所以容器实际上没有做虚拟化,它们还是运行在主机上一个个普通的进程,只是我们人为隔离了它们的资源。可以说,隔离是容器化的核心思想。相比起虚拟机,容器减少了指令翻译的损耗,运行起来也就更快。而且由于并没有启动多个系统,因此非常节省内存。
容器除了隔离,我们还可以有选择地在容器间共享资源。比如应用 A 和应用 B 都跑在 Ubuntu 18.04 (宿主机可能并不是这个系统版本)里,那么容器 A 和容器 B 就可以共享系统文件,主机上只用存一份镜像即可,相比起虚拟机,节省了大量的磁盘空间。
不过,虽然 Linux Namespace 提供了隔离机制,但却没有办法像虚拟机一样控制不同容器使用 CPU 和内存的限制,为此,还有另一个重磅技术 CGroups(Control Groups)来限制资源的使用。操作系统管理着所有的进程和线程,自然也知道不同进程和线程 CPU 和内存用量。CGroups 实现的思想也非常简单,开放一个接口让用户设置限制值,然后对比进程是不是超过限制量就可以了。
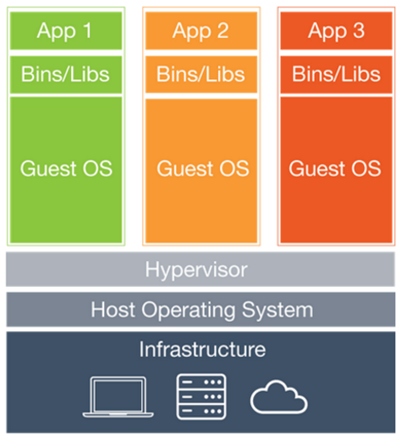
LXC 基本实现了虚拟机的隔离和限制的功能,同时在性能上有着无可比拟的优势,因此也被称为“轻量级虚拟化”。不过,由于涉及较多内核的功能,使用起来还是略显麻烦。为此,2013 年 dotCloud 公司将复杂的容器封装成简单易用的 Docker 工具并开源,让容器的打包、下载、运行变得十分方便。从此应用的部署就可以抛弃昂贵的虚拟机,转而使用容器化部署了。
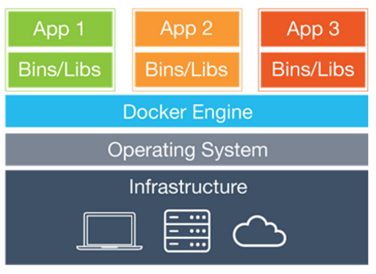
要是每个应用都重新做一个容器,那就会显得太麻烦,也太占空间。这时候轮到 aufs、overlayfs 等分层文件系统大显身手了。Docker 构建容器是一层一层地构建的,就像 git 一样,我们每次往容器里添加、修改或删除文件的时候,我们并不是直接在镜像中直接修改文件,而是会建立一层新的文件层,记录着变动。为此,我们可以先构造一些基础镜像,比如一个装好 Python 3.7 的 Ubuntu 18.04 镜像,后续我们就直接在这个镜像上直接添加新的层来构建我们的应用镜像即可。而 Docker 下载镜像的时候,就会看看这个镜像哪些层已经下载过了,到时候直接共享给不同容器即可,只下载没下载过的层,这样既节省流量,也节省空间。
而这些基础镜像往往都是大家非常需要的,于是 Docker 推出了注册表的功能,上面记录了有哪些镜像已经被制作过并被上传了,这样其他开发者需要使用的时候,就不用再自己制作了,直接从注册表获取制作好的镜像就可以跑得欢了~就像 GitHub 托管了源码一样,DockerHub 托管了许多公共的镜像。我们也可以自己搭建一个 Docker 注册表,就像我们可以使用 GitLab 自己搭建 Git 仓库一样。
就这样,Docker 几乎完美地解决了应用的打包部署问题,我们开发好的应用就连着环境一个个地被打包进集装箱中,运往不同服务器,然后被运行起来,提供服务。当然,平时我们想用一些新版本的环境做开发,也不用费劲到处找二进制包,甚至下载源码编译了,我们只需要从 DockerHub 拉取镜像,就能在几分钟内跑起一些配置复杂的软件了~
持续交付:CI 与 CD
在我们编写好代码之后,我们可能需要编译、测试、打包和部署。而一次又一次地将代码传到服务器上,然后执行命令,不仅效率低下、重复繁琐,还极有可能出偏差,要负责任的。俗话说,程序员只会做同一件事两次,因为第三次的时候已经是自动化脚本了。
在 Git 中,其实我们每次操作都会触发一些脚本,这些触发点就叫做 Hook(钩子),例如我们在 commit 之后,会触发 commit 的钩子,push 之后,服务器会触发 receive 钩子。通过这些钩子,我们就能实现许多自动化操作。
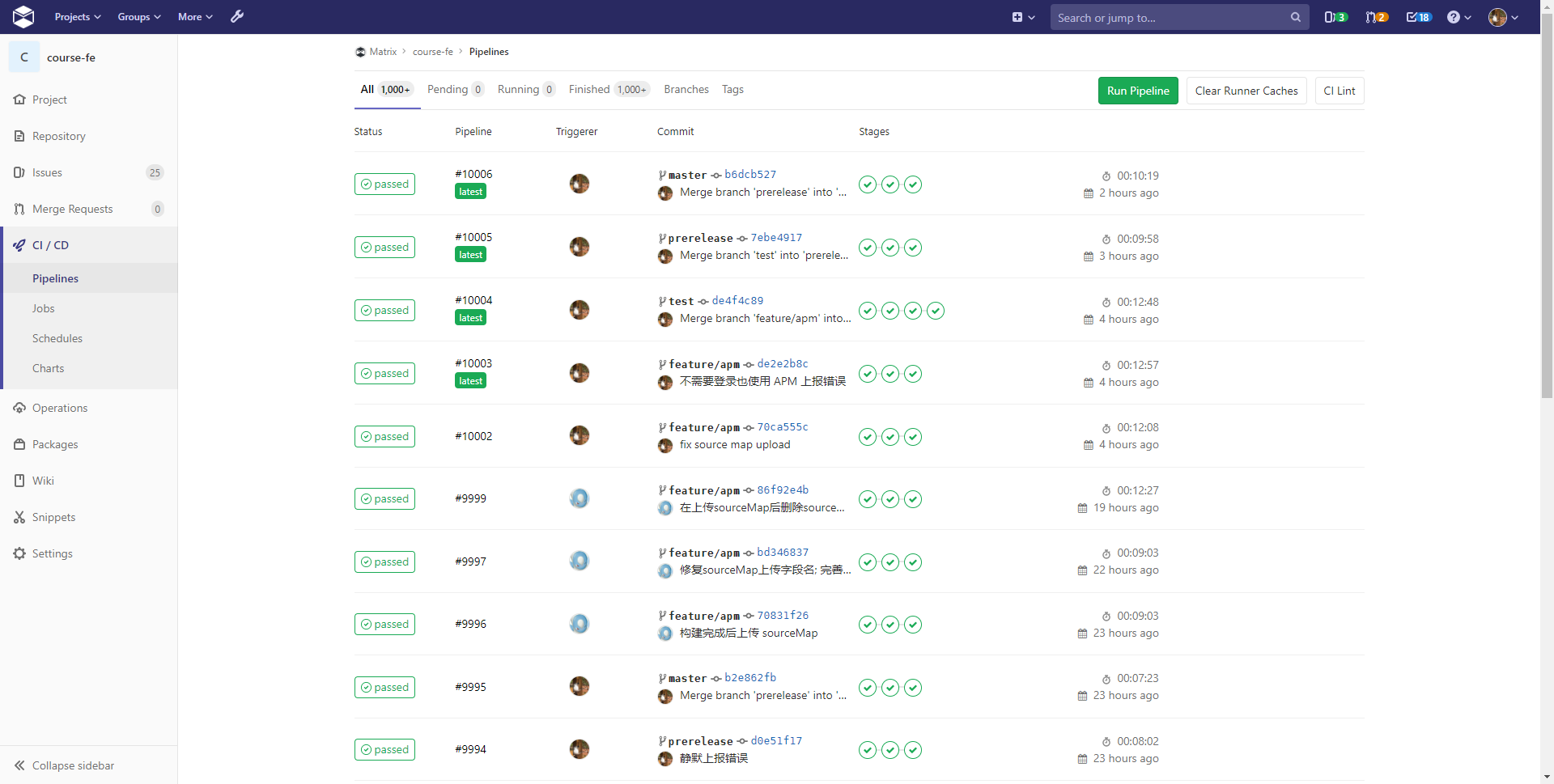
CI 指的是 Continuous Integration(持续集成),集成的意思就是将你所做的改动合并到现有代码中,看看能不能编译通过,然后再运行自动化测试看看能不能通过全部样例(听起来是不是很像你在 Matrix 上做题[奸笑])。
而 CI 通过后,我们就可以准备部署了,这时候就进入了 Continuous Deployment 阶段,持续部署。在这一阶段,我们通过一系列预先定义好的命令,将编译好的应用连同运行环境一起打包成 Docker 镜像,发布到 Docker 注册表中,并且通知运行着 Docker 的服务器拉取新版本应用、停止旧版本应用并运行新版本应用。
通过 CI/CD,每次我们推送代码之后,都会全自动地将我们的代码部署到服务器上,全程不需要我们到服务器上执行一条命令。哪怕开发人员对服务器运维并不熟悉,也不妨碍他发布新的代码,提高了效率。
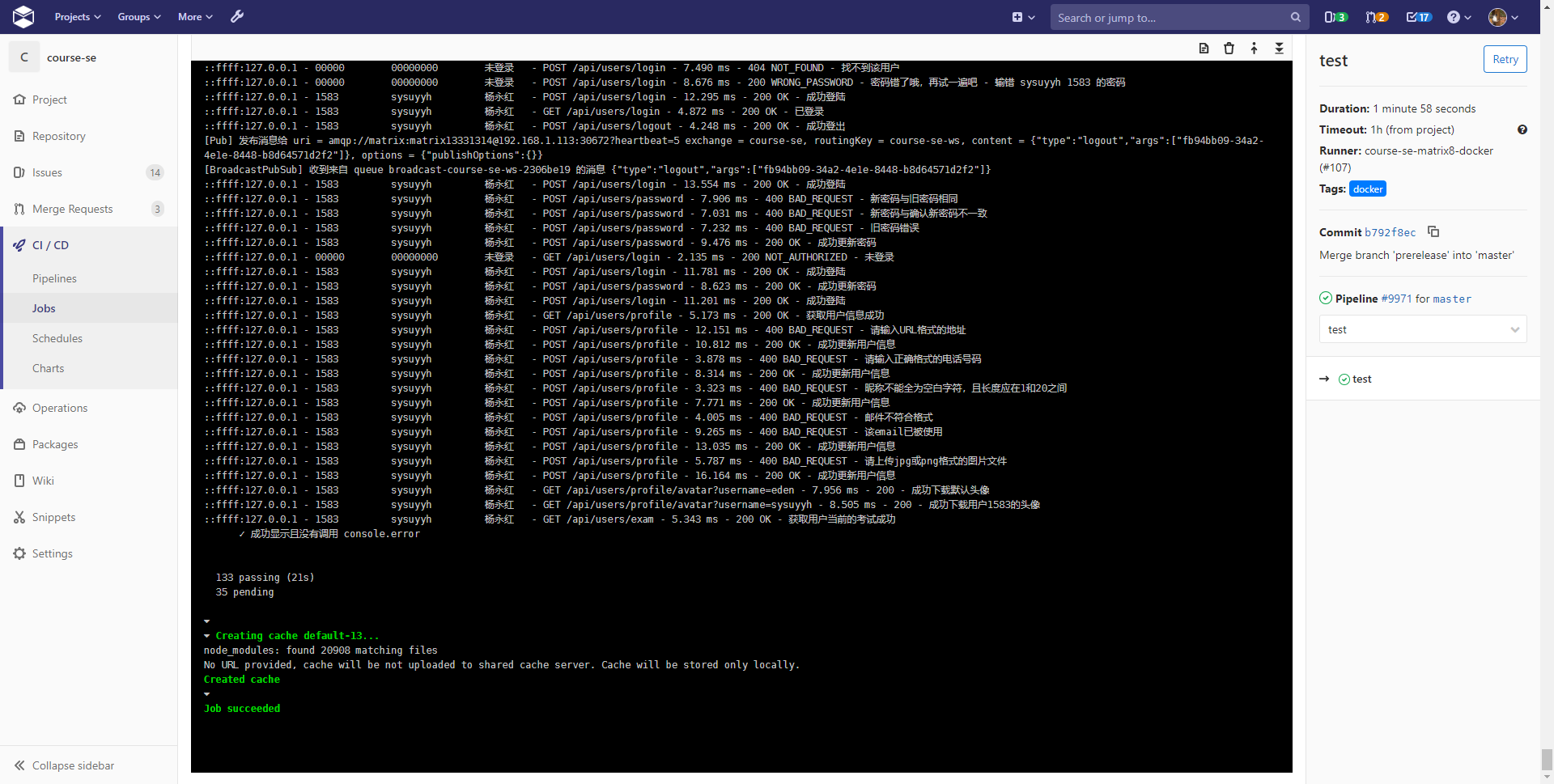
而在这个阶段,Matrix 发布服务的方式是在一台指定的机器上运行 CI Runner,负责将代码打包成 Docker 镜像,并在本地运行起来,然后通过端口暴露的方式,将容器内部的网络开放给其他机器。而如果应用需要互相访问,则可以使用 IP + 端口直接访问。
容器海洋的掌舵人:Kubernetes
当我们开发的应用逐渐增多时,麻烦就逐渐显露出来:我们需要小心翼翼地分配 IP 地址和端口避免冲突。为了避免冲突,我们手动维护了 IP + 端口与服务的对应表,当我们需要发布一个服务的时候就先查找这个表,看看有哪些空闲的端口,然后往表里写一条记录。而当我们想知道一个服务发布在哪里的时候,就要反过来查这个表。很显然,我们在做 DNS 做的事……同时,我们每发布一个应用,就要手动调整反向代理的配置,增加新的虚拟服务器,指向我们发布的应用。
有时候一个容器不足以应付高并发流量,又或者为了避免单点故障,我们会选择在不同的机器上部署相同的容器,这样即使其中一个机器宕机,也能继续正常提供服务。这样,我们就还得手动维护一个服务都在哪个地址提供服务的表。而应用想访问其他服务的时候,我们就把所有的地址都写到配置文件中,然后再由应用去选择一个能用的地址访问服务。或者,我们会利用反向代理的负载均衡功能,将服务写成一个固定的域名,到时候应用如果需要访问服务,则直接交给反向代理选择一个服务实例进行服务。
然而,这仍然无法处理实例动态伸缩的问题,当我们增加或者减少服务容器的数量的时候,我们还是要手动改配置。随着服务的增多和变动的频繁,手动更改配置缺点逐渐显露出来,不仅非常繁琐,而且非常不灵活。
而且我们现有的 CI 模式导致了无法将容器部署到与打包不同的机器上,这就导致如果我们想开启多个进程进行负载均衡时,只能在单机上开启多个容器,或者甚至直接在单个容器内开启多个进程。
可以看到,当前的服务部署模式极度依赖手工操作,非常不灵活。那么对于一个服务器集群,我们应该使用什么样的工具进行管理呢?
对于这个问题,Google 是当之无愧的领头羊。为了管理大规模计算机集群,Google 内部开发了一套工具,称为 Borg,使用了十多年,并发表了相关的论文。不过,Borg 本身并不开源,但是 Google 吸取了十多年来集群管理的经验教训,开源了一套管理容器的系统,称为 Kubernetes(简写 K8s)。这个单词源于希腊文,意思是掌舵的人。一个个容器就像集装箱被运上货船,由 Kubernetes 载着他们到不同的港口,最后卸货拆箱运行。
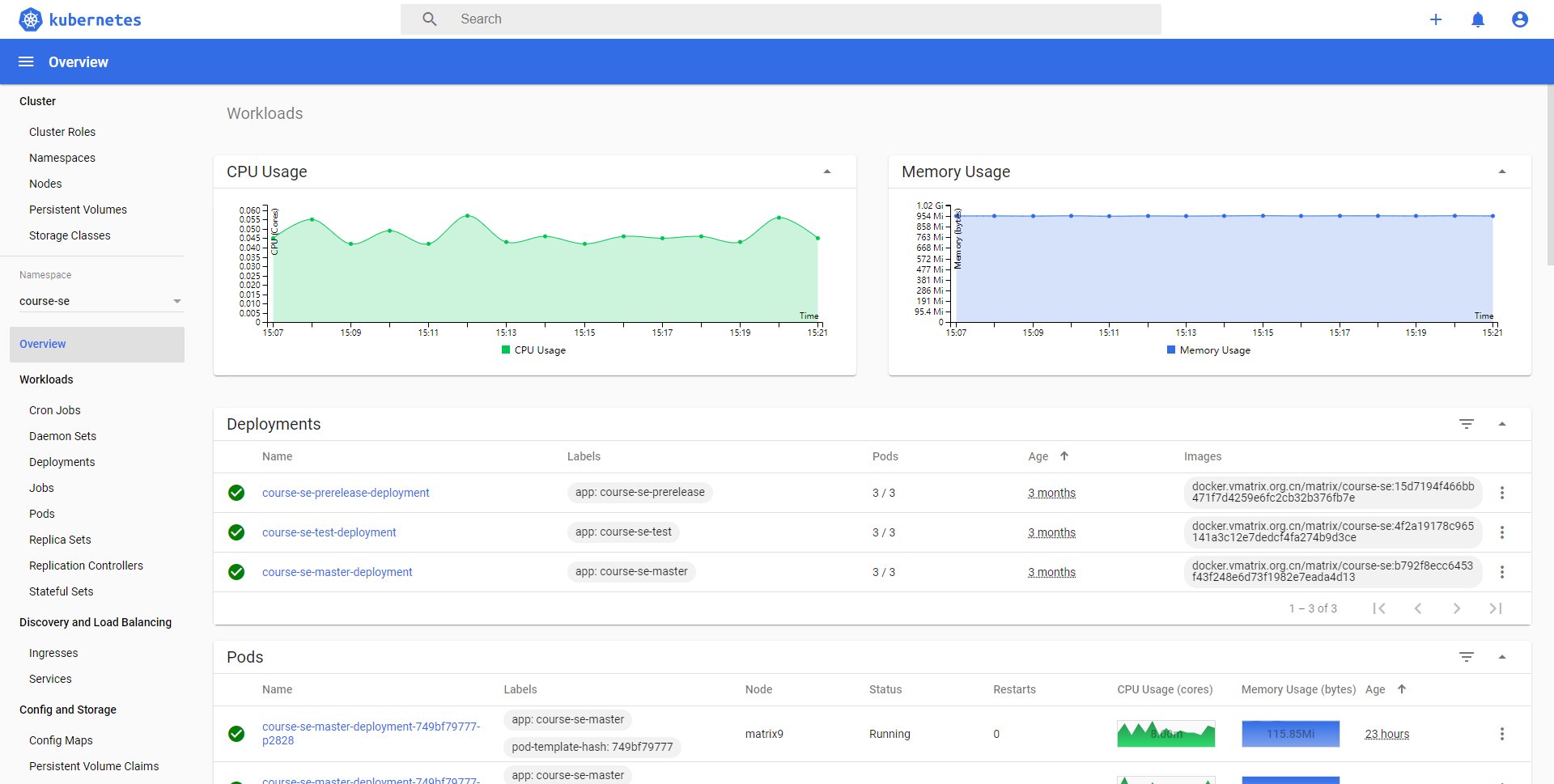
K8s 就像一个船长,我们只需要告诉船长我们想要到哪里,他就会负责帮我们完成剩下的工作。我们只需要告诉 K8s,应用 A 需要运行 3 个实例,应用 B 需要运行 5 个实例,K8s 就会帮我们妥善安排好机器资源,将容器调度到上面运行。我们也无需手动一一安排每个机器上需要运行怎样的容器了。而在 CI 时,我们也不需要自己运行容器,只需要打包好镜像,并告诉 K8s 我们需要怎样部署这个服务,我们的服务就可以部署到集群里的其他机器上了。
Google 在使用 Borg 运行任务的时候,也直接使用了主机的 IP 地址和端口来提供对外服务,因此他们也遭遇到了需要维护一堆 IP 和端口的麻烦,应用也需要根据可用的端口调整自己的配置。不过,得益于网络虚拟化、SDN等等网络技术的发展,我们可以摆脱物理网络限制,给容器分配一个虚拟的 IP,这样就不需要占用主机上宝贵的端口资源了。在 K8s 的管理概念中,调度的最小单位是 Pod,每个 Pod 都有一个自己的虚拟的 Pod IP,一个 Pod 可以含有多个容器,而一个 Pod 里的容器共享同一个网络空间。一个 Pod IP 对外表现就像是一个正常服务的主机一样,可以 Ping 通,也能直接访问。
然而,这还是没有解决其他应用访问服务的问题,由于 Pod IP 并不是确定的,甚至是会随着 Pod 创建和销毁频繁变动,因此,K8s 还会帮我们管理一个服务对应着哪些 Pod,称为 Service。在我们部署应用的时候,会指定一个 Service 应该对应到哪些应用,K8s 便会将这些应用的 Pod IP 记录在 Service 里。而一个 Service 也拥有自己的一个 IP 称为 Cluster IP,不过这个 IP 比 Pod IP 稳定得多,但却表现得不像一个正常的主机。这个 Cluster IP 并不直接对应到任何可以被访问的实体上,而是一个中介。集群里的机器会在收到 Service 的信息时候,在机器上设置 iptables 规则,任何访问这个 Cluster IP 的指定的端口和协议的流量最后都会被转发到 Pod IP 上。所以 Service 的工作原理与反向代理并不相同。而这也保证了即使 Master 宕机,应用也能暂时正常继续运行。
万一一个 Pod 宕机了,那么 Master 就会将其从 Service 中除名,并通知集群机器重新设置代理,这样,流量就不会被转发到死掉的实例上。那么问题来了,K8s 如何知道一个 Pod 是否正常运行呢?它用的方式十分简单粗暴:我定时执行一个命令,或者发送一个 HTTP 请求到你的容器中,要是没反应或者出错了,那就认为 Pod 出错了,并暂时将其从 Service 中除名,然后重启容器,希望能恢复正常状态。我们写应用也无需对异常做过多处理了,我们就大胆放心的 Let it crash,出错了保存一下现场,然后重启就好了。
通过这种保活机制,在我们告诉 K8s 需要部署新版本的时候,K8s 并不会马上把旧的容器全部赶尽杀绝,火急火燎地上线新容器,而是会先启动一个新容器,等到确认它正常工作一段时间后,才会杀掉旧容器,然后再启动一个新容器,看看工作是否正常……这种方式就被称为滚动更新,这样通过一个个逐步替换的方式更新版本,确保了我们对系统的错误改动不会立即生效,保障了服务的正常运行。这样,我们发布新版本的时候就更大胆了,毕竟要是出错了,K8s 还会尽职尽责地帮我们守住服务呢!
基础服务迁移
Web 后端与前端都是无状态的应用,很容易无痛上云。然而帮助其维持状态的基础服务如 MQ、Redis、文件系统等则是有状态的,要迁移会非常麻烦。而且当前部署的方式通通是单实例,我们还需要对基础服务进行集群化改造。这也花费了我们不少的时间。
对于有状态的应用而言,我们不仅需要为其分配存储空间,以免容器重启后数据全部丢失了,而不同的应用对于集群化部署也有不同的要求,甚至可能对容器的启动顺序有要求,所以还需要对其量身定制。分布式有状态的应用有一个棘手的问题,那就是状态在各个实例之间如何互相同步。假如你用过腾讯文档或者石墨文档等,想必你也好奇过大家的修改是如何同步的吧。就以数据库为例,假如现在有 A、B、C 三个数据库,那么谁可以写入呢?要是大家都能写,万一修改之间冲突了怎么办呢?如果只有一个实例可以写,那么又该如何选举呢?要是一个实例宕机了,集群状态怎么恢复呢?要是有一个新实例加入,又该如何同步状态呢?分布式有状态应用就好像一个小小的议会,可是大家都是兼职的,想来就来,想走就走,却又需要对很多规定做出一致的决定。
好在,计算机科学家们早已研究出许多种分布式一致性算法,例如 Paxos、Raft、Gossip 等。有的算法通过一阵猛如虎的数学操作,就让实例之间通过自己保存的状态以及对方发来的消息,来使整个集群的大多数节点在数据上达成一致。而有的算法同样通过猛如虎的数学操作,钦点出一个专门负责写入的 Leader,其他实例则成为 Follower,乖乖从 Leader 接收数据。Leader 要是没有了,就再通过一阵猛如虎的操作选出新的。当然还有的通过一阵猛如虎的哈希操作,将不同的读写请求分配到不同的实例上,当然分区之间有冗余,要是分区的备份数不够了,就想办法复制出来一份。这样保证了数据在大多数时候都可以访问,即使有少数实例莫名其妙宕机,也不会严重影响集群的状态。
不过还有一个问题,那就是节点之间如何发现对方呢?就像你想拉几个好友群聊,总得想办法加微信好友吧。在比较传统的部署下,IP、实例数量等相对固定,我们大可以直接将所有的节点信息写到每个节点的配置文件里,相当于让每个节点都事先认识对方,拉群聊也就很方便了。但是在 K8s 环境下,我们没有固定的 IP,也没有固定实例数,又该怎么让他们发现对方呢?
好在 K8s 也早就支持了对于有状态应用的部署,K8s 会专门为有状态应用的每个实例提供一个一致的可预测的稳定的主机名标识符,无论 Pod 如何变动,都拥有一个不变的标识符,并且总会按顺序启动。例如我们的应用叫 mysql,那么 K8s 就会按顺序一个接一个地启动 mysql-0,mysql-1 等等。我们可以像链表一样将这些实例连在一起。更有的应用提供了 K8s 插件,可以直接从 K8s 中获取自己的伙伴信息。这样,我们的基础服务也可以欢快地跑在 K8s 上了。为此,我们还使用了一台专门的 NFS 服务器,提供网络文件系统服务,这样,K8s 就可以利用 NFS 来供集群中的机器进行读写了。
然而,有状态应用的迁移,不仅需要分配存储空间,还要保证现有的数据也一致地迁移到新的服务上。也许你会说,我直接把文件复制粘贴一下不就好了吗?然而,我们的系统几乎每时每刻都有人在使用,也就意味着数据库可能随时在更新、不断地有新的文件写入系统,同时,原有的数据也是海量的,这意味着如果我们想停服迁移,可能花上一天也未必能搞定,然而不停服的话,中间的数据便有可能丢失,这就像是要给一辆飞驰着的火车换轮子一样难。
不过,难也要顶硬上,首先开刀的是文件系统,由于 Matrix 应对的是大量的小文件,我们并没有直接将用户的提交直接粗暴地存放在 ext4 等通用操作系统上,而是选用了 SeaweedFS 来存储我们的提交以及测试数据等,这个文件系统实现了这篇 Facebook 论文的算法,提升了小文件存储的效率。而文件系统使用了 Docker Compose 部署,将宿主机目录挂载到了容器内部,因此我们天真地以为只要将目录里的东西复制到 NFS 上,然后重新挂载目录即可。可令我们万万没想到的是,我们没有办法读取出任何文件!噢,上网一搜,原来是我们原来的 SeaweedFS 很久没更新了,新版本的 SeaweedFS 早已不兼容旧版本的数据格式。这时心中一万头草泥马奔腾而过~然而更危险的是,原有的 Docker 镜像部署直接使用 latest 标签,要是那一天我们不小心更新了原来的镜像,那可真是欲哭无泪了。不过,抱着软件版本升级一般会提供相应的数据升级工具的想法,我们去 SeaweedFS 的 Wiki 搜寻了一番。OMG,结果作者并没有提供这样一种工具!无奈,我们只好选择自己写脚本。为了保证文件不丢失,我们还先修改了应用的代码,在用户上传文件的时候,同时写入新旧文件系统,然后便开始了漫长地导出、打包、导入 210 万个小文件的过程……终于,花了两天时间,我们成功地把文件系统不停机地迁移了,给火车换上了新轮子。
之后是 Redis 迁移。Redis 主要用于数据库缓存以及 Session 状态存储。Redis 集群部署有两种选择,一种是 Sentinel,一种是 Redis Cluster,各自都能实现高可用。本着学习的心态,我们选择了 Redis Cluster 部署。对于这种部署方式,其 Key 采用了分区存储的方式,因此我们需要改造原有的 Redis 客户端代码,使其能够处理 Redis 集群连接。而 Redis Cluster 的建立需要在集群所有节点正常启动之后才能进行。这时候,连 K8s 强大的管理能力也显得有点捉襟见肘了。幸好集群一旦建立便是一劳永逸,所以我们选择了先直接启动好 Redis 节点,然后在其中一个容器里执行集群初始化命令。等待集群正常运行之后,我们就直接粗暴地将服务指向新的 Redis 集群,已登录的用户也因此被通通踢下线。不过当时已经是深夜,因此被踢下线的用户并不多。
而我们与评测系统通信、或者广播实时通知使用的消息队列 RabbitMQ,则迁移难度小了很多,由于消息丢失了我们也有办法重新发送,因此我们直接选择了上线新版本的服务,运行正常后直接切换到 RabbitMQ 集群上,然后重新发送丢失的消息,就完成了迁移。
而最让人头疼的,也许就是数据库了。如果说登录状态丢失了大不了再登录一次,评测消息没有发送出去大不了再发送一次,数据丢失了,那就没有办法挽回了。所以,对于数据库而言,我们仍然要如履薄冰,万分小心。不过,互联网上也有许多的开源方案可以供我们参考,其中最知名的莫过于 GitHub 的 orchestrator。我们当然是拿来主义,学习其中的思想,然后部署在我们的服务器上,搭建了数据库的集群。
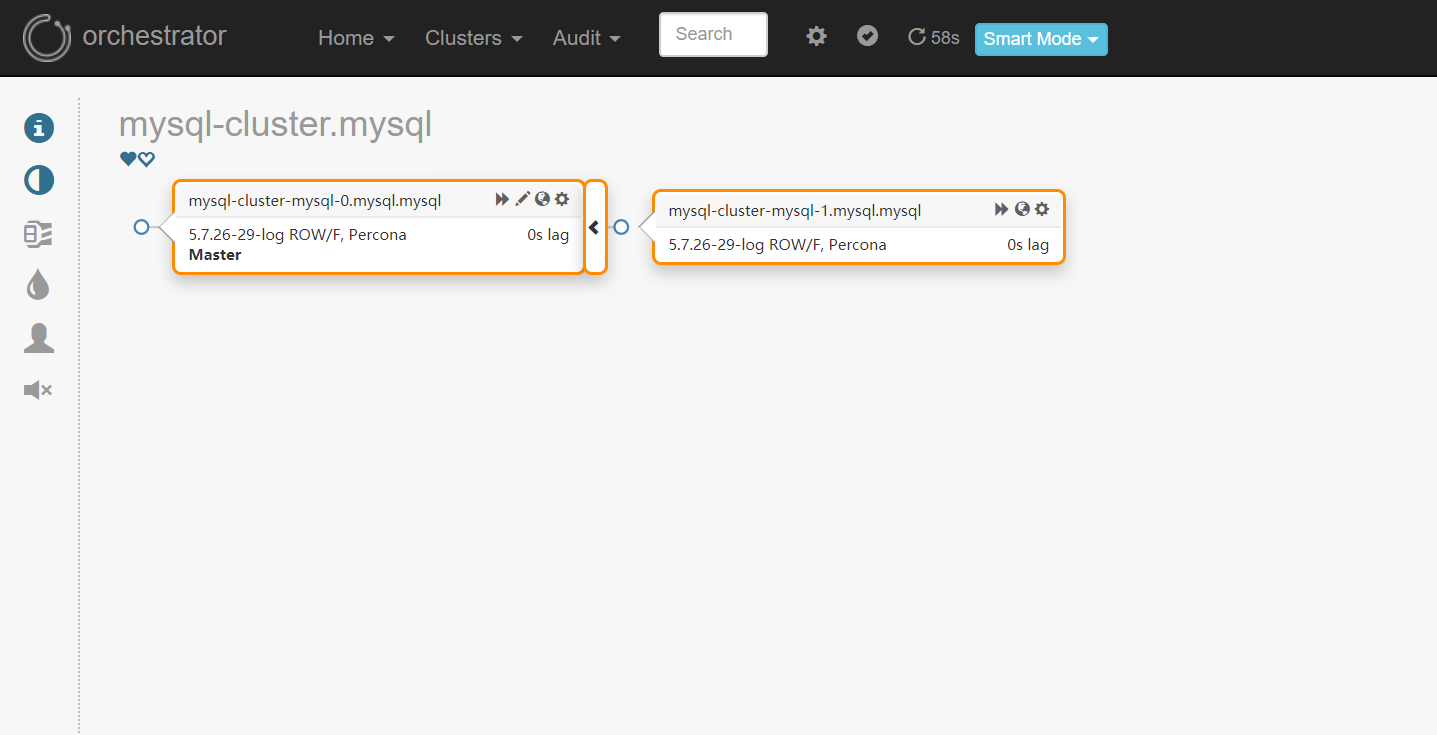
当然,数据库的迁移是更加困难的,通过观察日志发现,我们的系统几乎 24 小时都有人用,而当深夜的时候虽然没有什么人用,但是我们也想睡觉。所以,如何完成数据库的不停机迁移也成为了一个大难题。首先当然要将当前的数据库备份一下,如果为了数据一致性而采用锁库锁表的方式,显然会对服务造成一段时间的影响。因此,我们必须依赖于 InnoDB 存储引擎的高级功能,通过拷贝物理文件快照,并在拷贝过程中不断记录快照后发生的事务数据,实现不停机的数据导出。然后,我们只需要将快照后的事务数据在物理文件上“重放”一次,就能恢复完整的数据了。当然,启动新的数据库后,仍然存在着数据上的时间差。为此,我们将新的数据库设置为从库,从旧数据库中及时同步新产生的数据。最后,我们选取了一个低峰点,将所有数据库设置为只读状态,同时修改所有服务配置指向新数据库地址,最后将旧数据库关机,新数据库设置为可写主库,就完成了一次(几乎)不停机的数据库迁移了。
不过,由于我们采用的是主从复制模式,只有主库可以写,如果读写压力都集中在主库上面,则有可能造成瓶颈。我们可以借助 ProxySQL 的工具,来将读数据库的压力分散到整个集群,这样我们就能充分利用数据库集群的性能了。
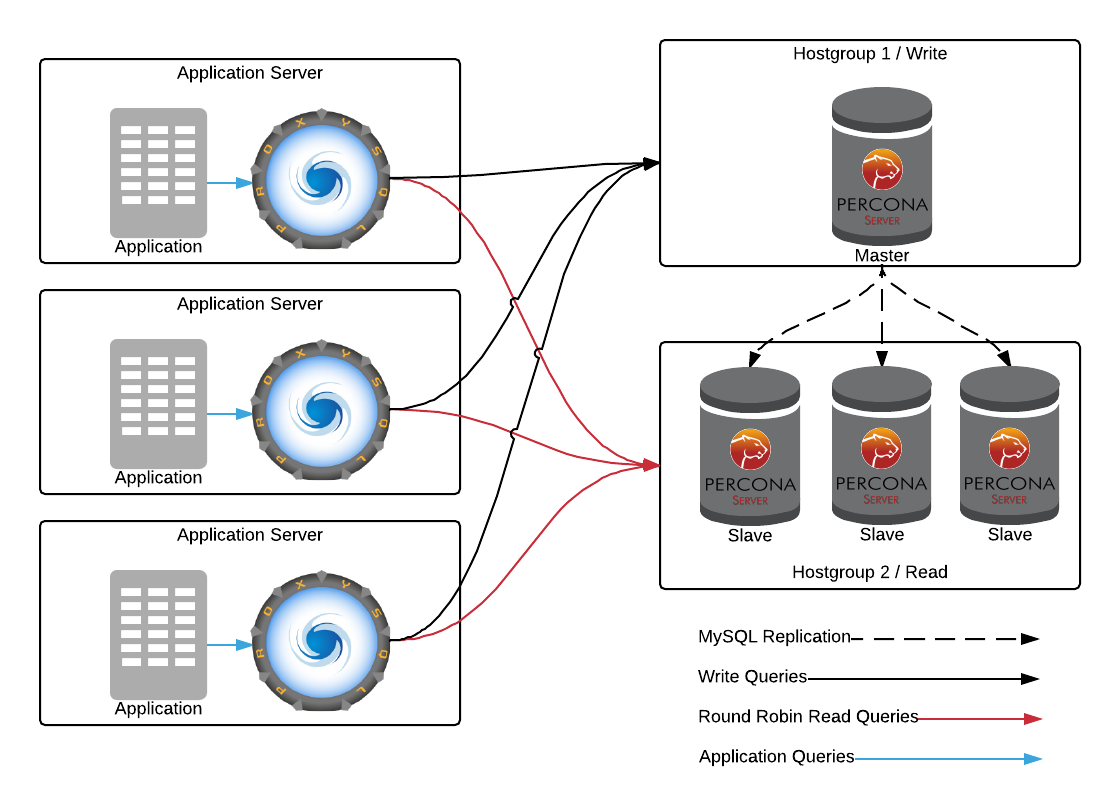
到这里,棘手的有状态服务迁移也就告一段落了,数据的安全性和可用性得到了进一步保障。
The Big Brother is Watching You
如果有一辆没有仪表盘、没有后视镜、挡风玻璃也脏的看不见前面的路的车,你敢开吗?也许运气好,前面的路一马平川,闭着眼睛踩着油门也能让车撒了欢地跑,但我们完全不知道这辆车的方位、速度,更不要提控制这辆车了。因此,为了更好的控制集群系统和其中的服务,我们必须建立一套完善的监控体系。
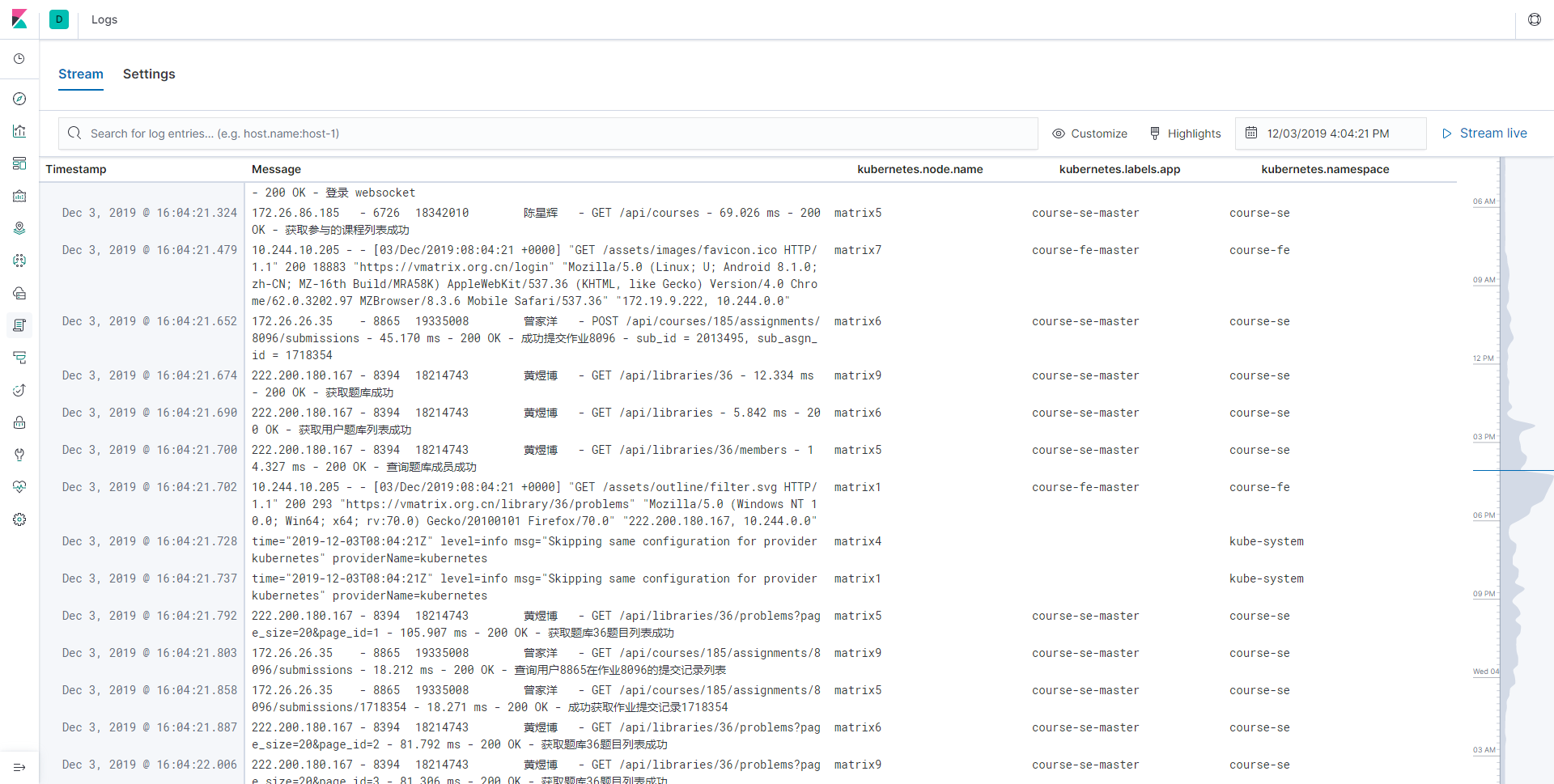
首先要解决的是日志的收集。尽管我们在写程序的时候就已经做了充分测试,可是难免上线之后出这样那样的 bug,线上的 bug 我们没有办法预知,也没办法直接在上面挂载调试器,而且很可能出错之后进程就被自动重启了。这时候,我们唯一能依赖的就是日志了。日志是什么,就是 printf,就是 cout,就是 print!
而这其中的挑战是服务是分布式部署的,我们没有办法像从前一样在一台机器上,绑定一个文件夹到一个容器上来收集日志。好在,这也是被工程师们精心解决过的问题,只要我们在每个机器上都运行一个收集所有容器产生的日志的进程,打上标签、做一些预处理、过滤掉不需要的日志,并且再从这些进程统一收集处理好的数据,不就好了吗?Fluentd、Logstash、Filebeat 等等都是这样的工具。不过,还有一个问题,我们要怎么收集这些数据呢,是由数据库去定时拉取,还是由进程主动上报?对于日志收集而言,由于日志产生速度比较快和多,如果定时去拉取,会造成缓冲区的堆积,影响机器性能,因此会采取进程主动上报的模式。
如果你用 printf 等等打印一堆东西来调试程序的话,一定会遇到数据量太大的问题。对于日志也是这样,一个正常的服务很可能每秒都会产生大量的日志,更不要说分布式部署带来的倍数增长了,在海量的日志里,我们不可能肉眼一条条去看,就像我们上网冲浪,也不能一个个网页点开来看,需要借助搜索引擎。收集完日志后,我们同样需要一个搜索引擎来帮我们快速找到我们感兴趣的日志,而 ElasticSearch 就能对进程上报的日志进行索引,帮我们快速找到日志。
不过,ElasticSearch 本身只能通过 REST API 操作,如果我们自己写一个前端又太麻烦,好在,工程师们也早就写好了一个 Web UI 供我们操作 ElasticSearch,那就是 Kibana。通过 Kibana,我们可以使用一种叫 KQL 的查询语言,快速查询我们需要的日志信息。更强大的是,我们可以通过提取日志中的信息,来构建一些统计数据的可视化。
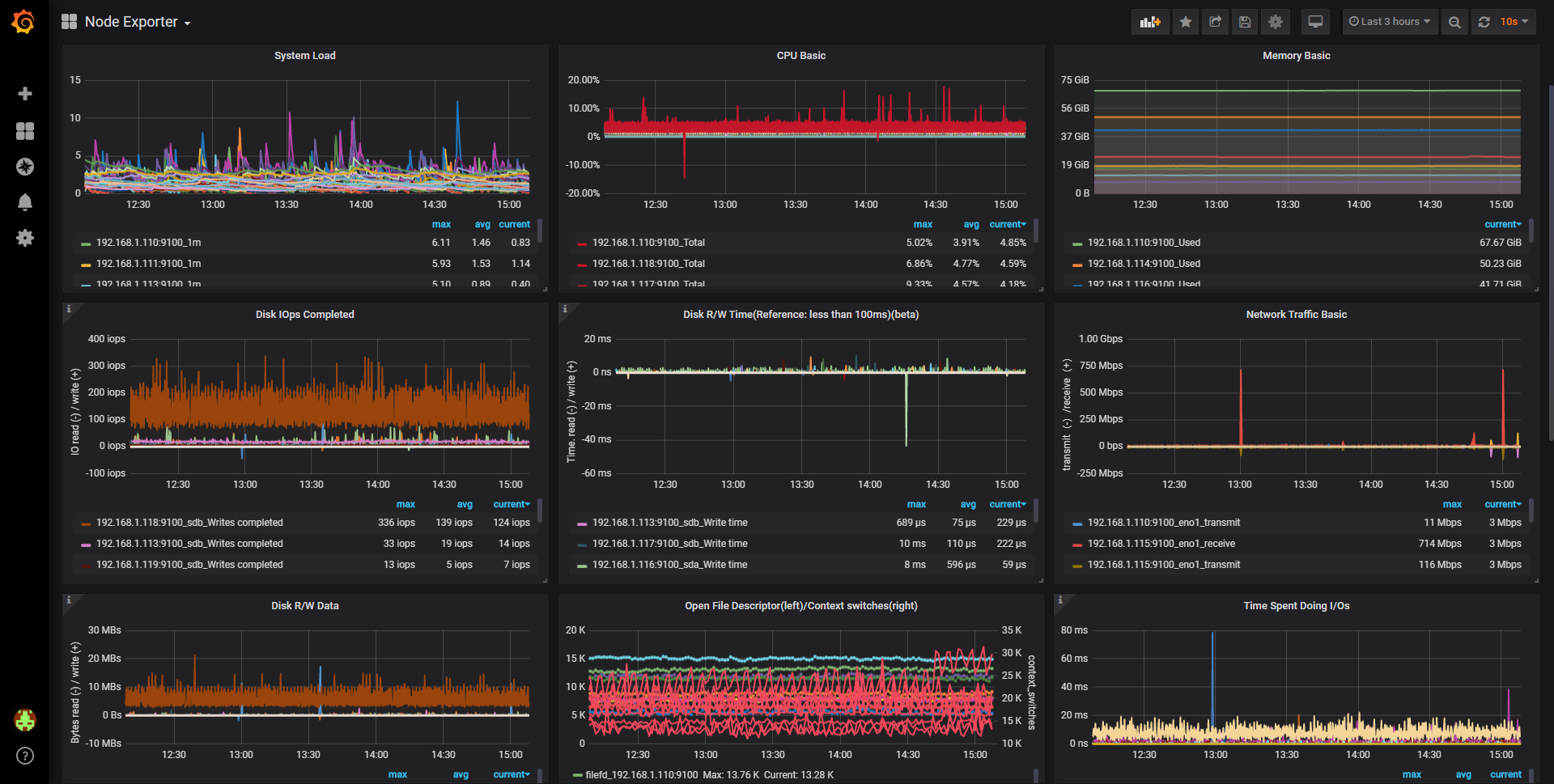
除了日志,我们还需要对机器、应用的实时指标进行监控,比如 CPU、内存、硬盘、数据库连接等等,并且在出现异常的时候及时报警,对于这些数据,我们并不需要多么强大的文本查询功能,因为都只是数字而已,如果使用 ElasticSearch 反而会有点杀鸡用牛刀的感觉。不是不行,而是太过笨重与别扭,配套的工具也不是很好用。
对于这种场景,Prometheus 会更合适,这是针对数值时间序列优化过的存储与搜索引擎。同样地,我们需要在每个机器上安装监控程序,称为 Exporter,负责将指标“导出”给 Prometheus 服务器,但相比日志收集,Prometheus 采用了主动拉取的模式。这是因为指标每时每刻都在变动,不像日志是离散的事件,所以有采样的概念。如果让采集器主动上报,那么很难保证每个采集器都同步上报,这样从不同机器收集到的数据就很难聚合起来。所以,Prometheus 会间隔一段时间,对配置中的所有采集器进行一次拉取采样,并存储到数据库中。尽管 Prometheus 比 ElasticSearch 好在自带了一个 Web UI,但实在是过于简陋。为此人们又不辞劳苦地开发了一个 Web UI,叫 Grafana,事实上,Grafana 就是 Kibana 的一个分支版本。通过 Grafana,我们可以将数据以 PromQL 这种查询语言进行聚合、计算,并将得到的数据通过饼图、线图、柱状图等等方式可视化出来。通过 Grafana,我们从 IT 精英摇身一变监控室大爷。
当然,我们不能总是没事就盯着监控看,我们还有 Alert Manager 来帮我们监控异常状况。通过设置感兴趣的监控指标以及规则,Alert Manager 会定期检查指标是否在正常范围内,如果长时间异常,就会通过电子邮件、Web Hook 等方式通知运维人员。这样我们就能从人工监控中解放出来,又能及时的感知到异常状况进行处理了。
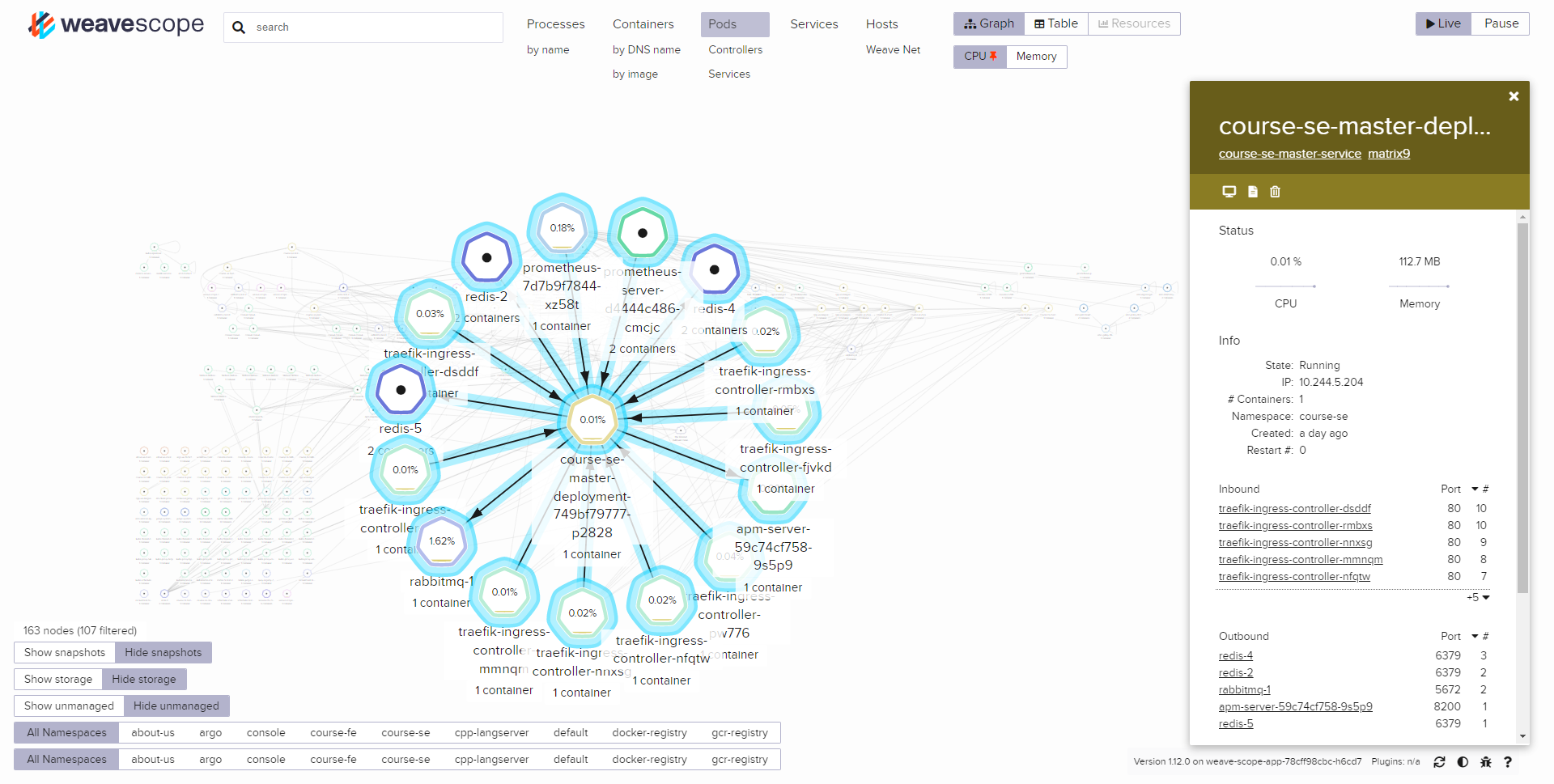
对于大量的服务,我们还需要知道一个服务都依赖于什么服务。尽管我们可以通过代码来获取依赖信息,但有时候通过图的方式能更直观地了解服务之间的调用链。 Weave Scope 则提供了一个观察服务。和日志、指标收集一样,Scope 会在每个机器上安装一个收集器,收集容器的网络状况,并以此构建出一幅逻辑图。这样,我们就能直观地在网页上看到一个服务都调用了哪些服务,又被哪些服务调用了。
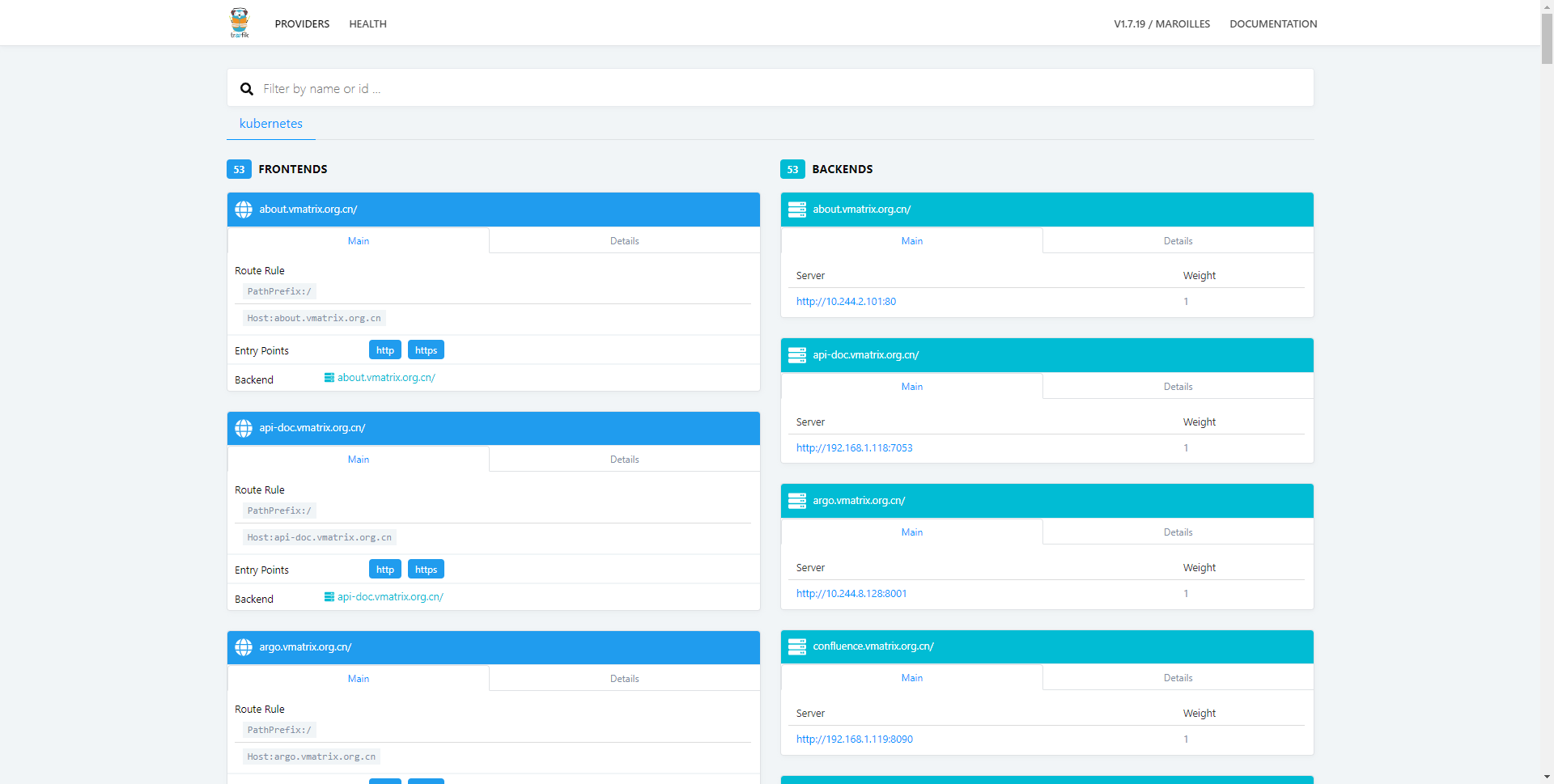
而对于我们对外发布的每个服务,实际上都是由 K8s Ingress 资源所控制的,而 Ingress 最终会被 Ingress Controller 所调度,因此,我们也可以通过监控 Ingress Controller 非常集中的看到我们发布的服务的状态。
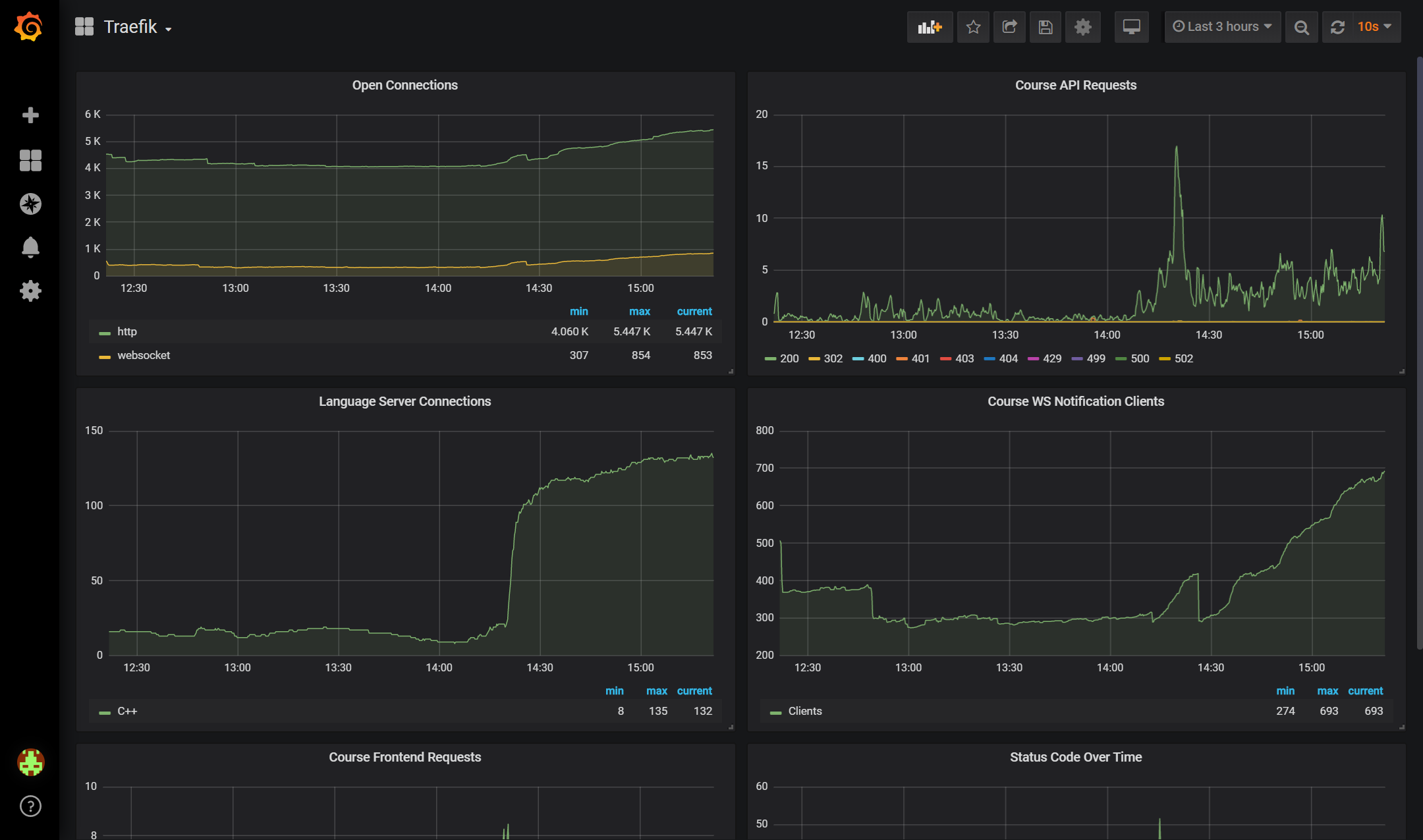
除了服务的正常运行,我们还希望能够对我们写的应用进行性能或者使用情况监控。对于数值型的数据,例如在线WS 用户数,我们会选择 Prometheus 进行监控。
而像数据库查询等等更深入的监控,则需要 APM 来帮助我们,通过直接修改库的代码,拦截所有的数据库操作,我们就能得到一个请求里到底进行了什么数据库操作:
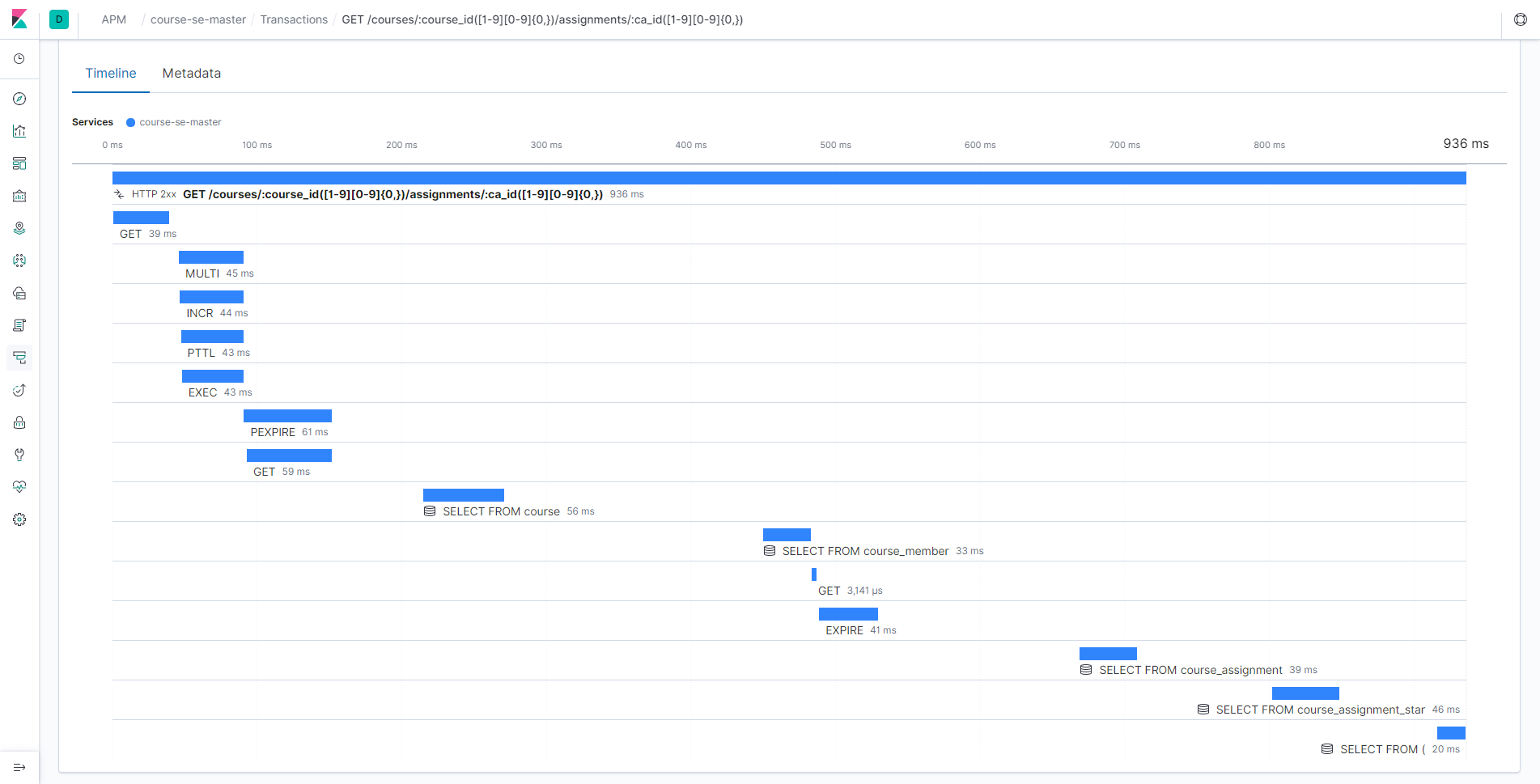
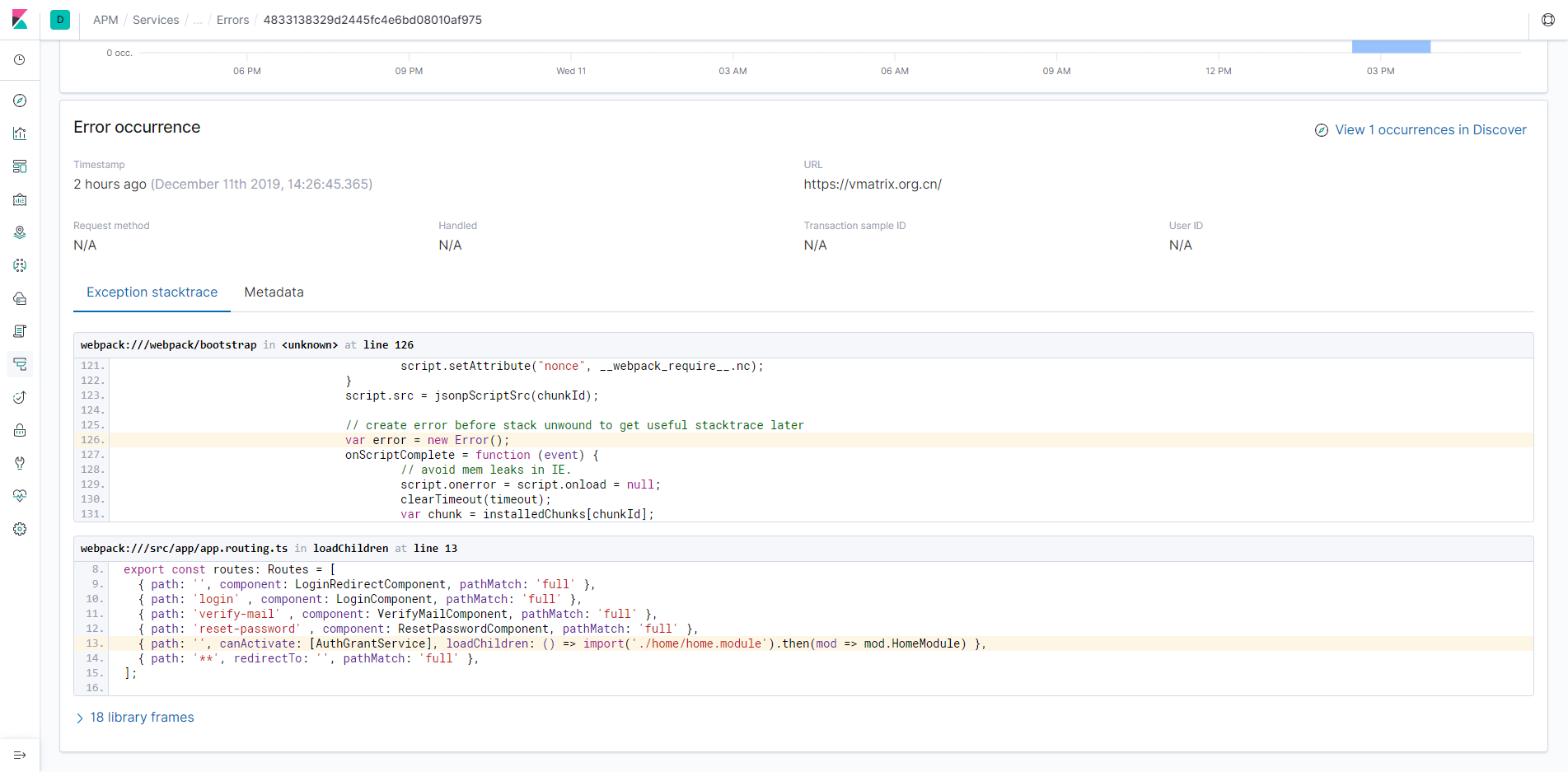
当然,我们还有一个最头疼的问题:前端的错误。如果说服务端发生了什么错误,我们还可以看 log 来排查 bug,那么前端出了问题,我们总不可能跑到用户的电脑上看控制台吧?所以,我们还需要在前端发生错误的时候上报错误,这样,我们就可以及时地定位 bug,而不需要麻烦用户帮我们排查问题了。
负载均衡与高可用
我们当然希望服务器的资源能被充分利用起来,所以,我们几乎所有的服务都以多个副本的形式部署起来。就像饭一个饭堂一样,开很多个窗口来应对络绎不绝的人流。当然,部署了冗余的服务之后,我们还能实现高可用,一个服务宕机了,还有其他服务可以使用,或者我们干脆再另外启动一个,替代掉宕机的服务。好在,K8s 会自动帮我们完成这一切,我们不需要关心我们的服务都运行在什么地方,也不需要关心怎么设置转发,一切都由 K8s 代劳。
那么问题来了,K8s 如何保证自己在 Master 重启的时候也可以正常运作呢?这时候我们需要对 K8s 本身进行高可用的改造。对于 K8s 的管理入口 API Server,调度器 Scheduler 以及控制器管理器 Controller Manager 而言,他们都是无状态的。而真正存储状态的,是 etcd KV 数据库。所以,K8s 本身也无非是一个 API + 数据库的典型 Web 应用。我们同样设置一个负载均衡器帮助我们自动选择可用的服务进行负载均衡,例如 nginx 等。当然,我们选择了专用于高可用的 HAProxy(High Availability Proxy,不是蛤Proxy)。显然,我们同样也不能只部署一个 HAProxy,而是同样的部署多个 HAProxy。那么这些 HAProxy 之间如何进行故障转移呢?这时候就请到了 keepalived 服务为我们守护。keepalived 通过一个自动漂移的虚拟 IP,来将一个 IP 绑定到能够正常提供服务的机器上。这个自动漂移的虚拟 IP 则是通过 VRRP(虚拟路由冗余协议)来完成”漂移“的过程的。

不过,我们还有一个问题没有解决,尽管集群内部的服务可以进行负载均衡,但是从集群外部进入内部的流量,我们还是只能集中地转发到其中一台服务器上。万一我们想重启这台服务器,那么我们的网站会直接无法访问一段时间,包括我们的一些开发服务。为了避免这种情况,我们必须针对外部流量也进行负载均衡。
由于我们没有负载均衡器,但好在我们的路由支持等价路由 ECMP 均衡,也支持 BGP 协议,所以我们可以通过 BGP 协议广播多条等价路由,由路由器帮助我们进行负载均衡。
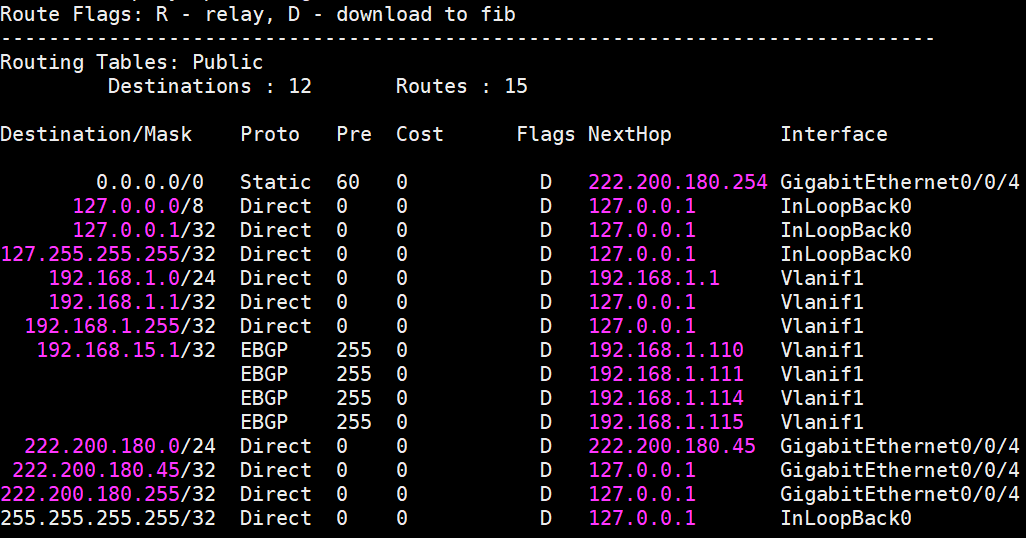
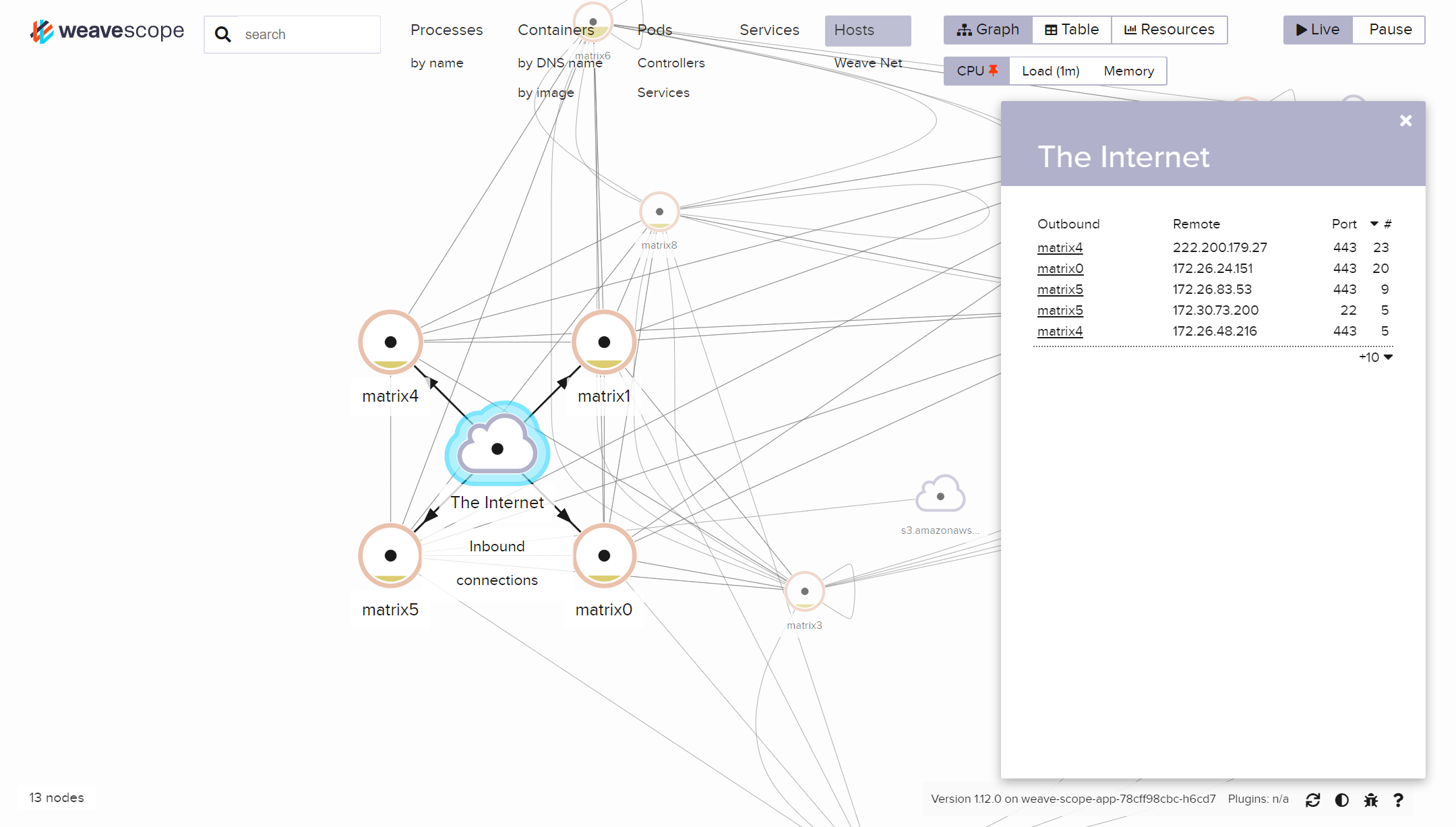
至此,即使我们有一台机器需要重启或者发生了故障,我们也不必担心会对服务造成影响,K8s 和应用集群会帮我们快速的 Fail Over,同时冗余性也保障了状态大概率不会丢失,服务的可用性得到了进一步的提升。
自动水平伸缩
在服务并不是使用高峰的时候,我们可能会关闭一些多余的容器,来释放服务器的内存和 CPU,节省资源;而到了服务高峰期,我们希望可以多部署一些实例,用来快速处理流量。因此,我们可以在完善的监控系统基础上,确定一些关键指标,例如 CPU 利用率、每秒请求数等,并且确定这些指标的目标,例如每个容器的 CPU 利用率不超过 50%,或者每个容器每秒处理的请求数不超过 100 等。当我们发现指标过小的时候,就可以缩减实例数,除非达到了最小限制,而当我们发现指标过大的时候,就自动扩展服务,从而应对高峰流量。
在 K8s 中,提供了 HPA API,用来帮助我们完成自动伸缩。

HPA 原理也很简单,它就像一个监工,隔一段时间就去取指标看一下,并通过算法计算出应该增加还是减少多少个实例,然后向 K8s 发出 Scale 命令,剩下的就是 K8s 的工作啦~
断路器
在服务之间调用的时候,可能会发生异常、超时等,而当一个服务发生大量错误的时候,说明很可能这个服务已经不正常了,又或者是过载了。对于这种情况,我们可以在服务链路上设置断路器。断路器就像一个保险,当我们发现一个服务不正常,就立即切断所有的流量。或许你会觉得这个很反直觉,断路了不是更用不了了么?让我们先来看看断路器的原理:
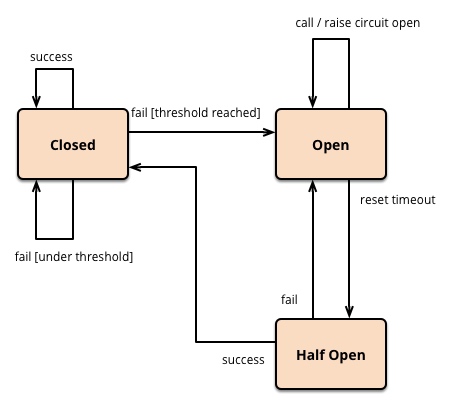
可以看到,断路器原理非常简单,只有三个状态:
- 最开始处于关闭状态,一旦检测到错误到达一定阈值,便转为开路;
- 这时候会有个 reset timeout,即开始准备恢复了,转移到半开路状态;
- 尝试放行一部分请求到后端,一旦检测成功便回归到闭路状态,即恢复服务。
不要小瞧了这个非常简单的原理,它符合 Fail Fast 这个架构设计准则,而不是一直慢慢 fail,等到 fail 一定程度后才让运维人员知道情况,其实也就我们常说的做事原则:不要隐瞒问题,而是应该尽快暴露问题。
让我们想象一下,服务 A 需要对数据库进行一个耗时的操作,在某个时间,突然大量请求涌入了服务 A,数据库压力开始上升,导致其他依赖数据库的服务也开始响应缓慢,而前端受到超时的影响,开始不断重试,导致更多请求进入队列,最终导致影响扩大,所有服务都几乎进入了不可用的状态。这就演变成了一场“雪崩”事故。
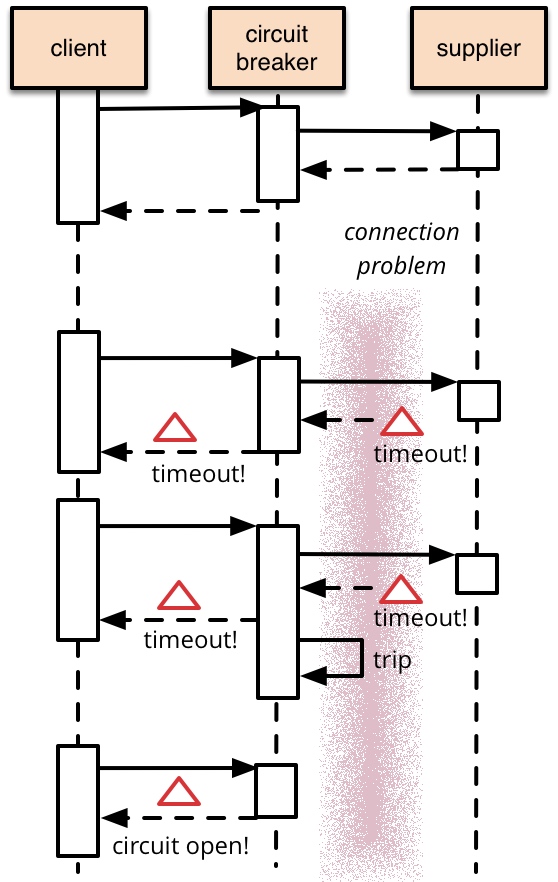
如果有断路器存在,我们可以在发现服务开始超时的时候立刻返回错误给客户,避免更多请求涌入服务 A,保护数据库,避免影响扩大。等服务 A 自然或者人工干预后恢复正常,再放行流量,从而避免波及更多的服务。
新一代云计算技术——Serverless
在目前的云计算中,最主流的还是 IaaS,也就是云服务器。尽管云服务器省去了维护物理服务器的麻烦,但是仍然要在启动的操作系统上部署应用,我们还是需要操心操作系统以及环境等。同时,我们的应用即使没有任何请求到来,我们仍然需要为云服务器所预留的资源付费。
服务部署所带来的各种麻烦,让我们不禁畅想我们有没有可能编写好一个函数之后就直接上云,不需要操心需要什么样的服务器,也不需要操心如何在服务器的操作系统上安装软件,更不需要操心监控、日志等更麻烦的事情。这时候就轮到 Serverless 闪亮登场了。Serverless 初看上去令人一头雾水,什么叫“无服务器”?其实我们的应用并不是真的不需要服务器就能运行,相反,我们的应用还是运行在真实的服务器上,只不过开发者在整个开发流程中,都无需接触服务器罢了。当然,Serverless 并不是仅仅只有 FaaS,实际上 Serverless = FaaS + BaaS。可以参考这篇伯克利发布的 Serverless 调研论文
使用 FaaS 部署一个函数有多方便呢?我们来看一个例子。假如我想开发一个简单的 Go 服务,那么我只要先将服务商提供的代码模板拉取下来:
faas-cli template pull golang-http然后用这个模板创建一个函数:
faas-cli new func --lang golang-http向其中的 handler 添加我们的代码:
package function
import (
"fmt"
"net/http"
"github.com/openfaas-incubator/go-function-sdk"
)
// Handle a function invocation
func Handle(req handler.Request) (handler.Response, error) {
var err error
message := fmt.Sprintf("Hello world, input was: %s", string(req.Body))
return handler.Response{
Body: []byte(message),
StatusCode: http.StatusOK,
}, err
}
编写完成代码后,我们可能需要对应用的环境变量等做一些配置:
version: 1.0
provider:
name: openfaas
gateway: https://openfaas.vmatrix.org.cn
functions:
func:
lang: golang-http
handler: ./func
image: func:latest
environment:
KEY: VALUE配置好之后,只需要简单的一句:
faas-cli up -f func.ymlBoom!稍等片刻,我们的函数就安然无恙的运行在了服务器上:
Deploying: func.
Deployed. 202 Accepted.
URL: https://openfaas.vmatrix.org.cn/function/func
$ curl -X POST https://openfaas.vmatrix.org.cn/function/func -d "hello, world"
Hello world, input was: hello, world过程中,我们也不需要关心怎么构建应用镜像,怎么连接到服务器上,怎么编写 K8s 部署文件等等麻烦的事情,几行命令就将一个简单的函数部署到了云上,让开发者可以更专注于应用代码的编写,而无需花费大量的精力到应用的部署和维护上。
通过这种细粒度的部署方式,我们可以更有针对性地为函数分配计算资源,甚至可以想象将许多用户的函数的调度抽象为装箱优化问题,让一个主机内的计算资源被充分利用。对于云服务商而言,计算资源的利用率可以大大提升,无需为闲置的 VM 预留资源;对于用户而言,也无需关心底层的系统维护,省出大量精力来专注于代码的编写,而且,用户只需要为函数的调用付费,如果函数没有被调用,甚至不会产生开销,也节省了成本。
当然,Serverless 也有其自身的不足,其天生就是为无状态的应用而服务的,对于像数据库等有状态的应用,Serverless 短期内仍然不适合,还是需要 BaaS 服务作为支撑。而大大简化的部署流程,也意味着用户的自主性变少了。同时,过于分散的部署会导致请求链路大大加长,使得延迟大大增加。而且,集成调试也变得更加困难……
作为一个或许还在萌芽阶段的新技术,其优点与缺点都还比较明显,尚无确定的标准,也需要更多的迭代,我们也许并不会用来开发一个完整的应用,但相信其简洁性和背后的健壮性,能开启云计算的下一个时代。
总结与展望
先来一张总体的系统图:
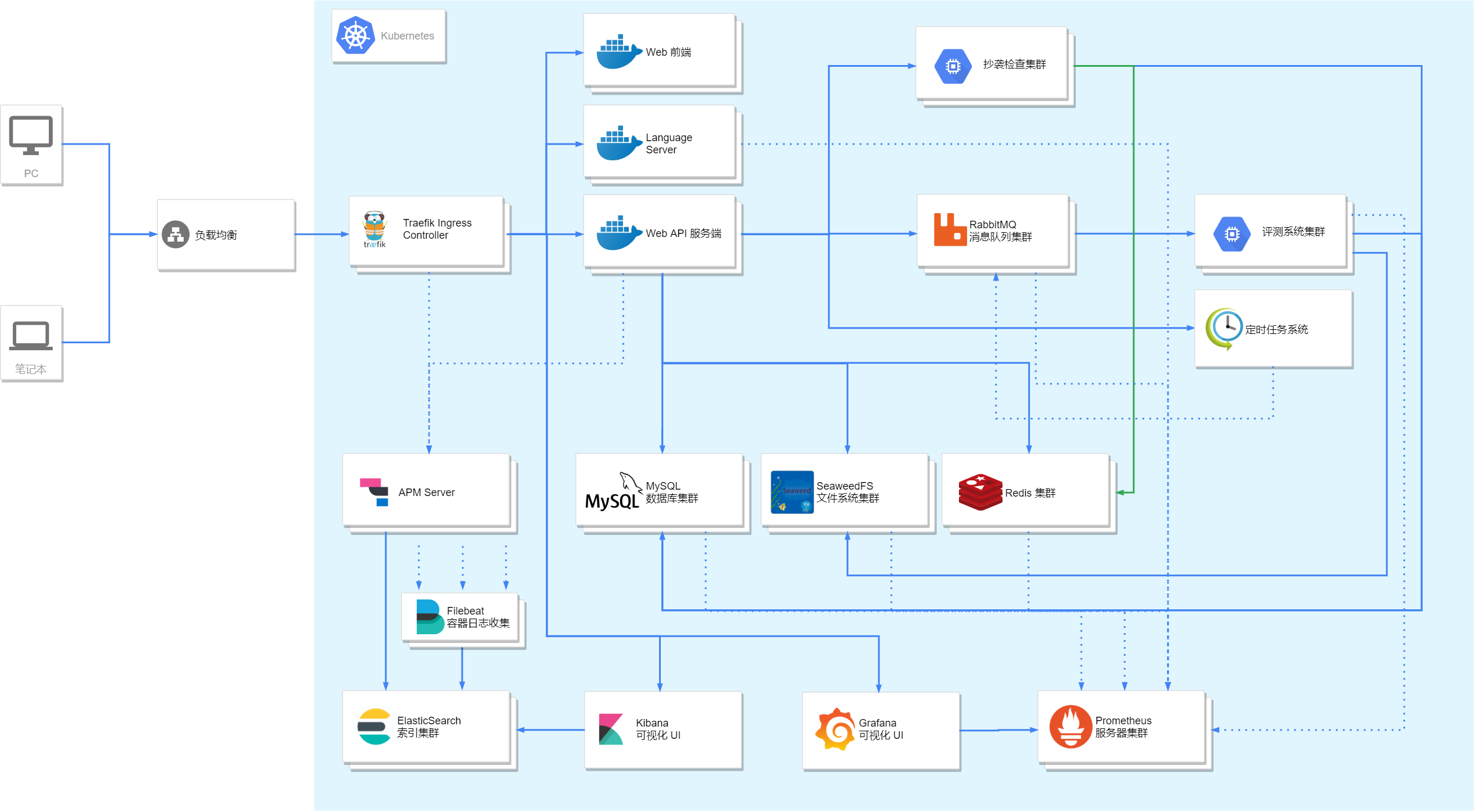
从前辈们筚路蓝缕用 PC 搭建起 Matrix 系统来,到拥有自己的小型服务器集群,再到我们搭建起私有云来,我们感受到了一代代精神的传承。尽管由于课余时间和精力并不充分,我们甚至不得不牺牲假期时间来维护开发这一套系统。不过,也正是在与各种奇怪的 bug 的斗争中,我们学习到了许多实战方面的经验;同时也深深体会到了那些看似枯燥无味的计算机基础课是多么的重要。没有计算机网络,我们可能难以搞定集群网络中复杂的路由;没有操作系统,我们可能难以构建起安全、高效的评测系统;没有数据结构,我们可能难以对收集到的海量数据进行进一步分析……
或许我们现在的系统仍然有这样那样的问题,甚至可能有许多错误,但是我们也正努力地用我们的学识与智慧来逐渐弥补一些漏洞。技术也在不断飞速发展,也许今天还热门的技术,不久就变成了明日黄花。不过万变不离其宗,在花哨的技术名词背后,是亘古不变的基础原理。所谓大象无形,大音希声,也许我们会一时乱花渐欲迷人眼,但相信在经历过看山是山、看山不是山、看山还是山的境界之后,我们能看破纷繁复杂的表象,牢牢把握住那统治着复杂系统的根基。
最后,技术永无止境,进一寸有进一寸的欢喜,也希望青出于蓝而胜于蓝,后面维护这个系统的同学能用更先进的知识来帮助系统构建的更完善。